

Unternehmen reden seit Jahren über Datenintegration. Die meisten meinen damit: "Wir haben irgendwann mal einen CSV-Export aus System A in System B importiert." Das ist keine Integration. Das ist ein Workaround, der spätestens beim dritten System zusammenbricht.
Echte Datenintegration bedeutet, dass verschiedene Datenquellen dauerhaft, automatisiert und widerspruchsfrei zusammenfliessen. Nicht einmalig, nicht manuell, nicht "bei Bedarf." Und genau diese Dauerhaftigkeit ist der Punkt, an dem die meisten Projekte scheitern.
Was ist Datenintegration?
Datenintegration ist der Prozess, bei dem Daten aus verschiedenen Quellen in eine einheitliche, konsistente Datenbasis zusammengeführt werden. Das Ziel: Jede Anwendung, jedes Team und jeder KI-Agent arbeitet auf denselben, aktuellen Daten, statt jeweils eigene Kopien zu pflegen.
Der Begriff klingt technisch, aber das Problem dahinter ist organisatorisch. Jede Abteilung kauft eigene Tools. Jedes Tool speichert Daten in einem eigenen Format. Nach ein paar Jahren existiert dieselbe Information an zehn Stellen, in zehn Strukturen, mit zehn leicht unterschiedlichen Versionen. Wer dann eine einfache Frage beantworten will ("Wie viele aktive Kunden haben wir in der DACH-Region?"), braucht drei Stunden und vier Tabellen.
Laut einer Studie von Gartner verlieren Organisationen durchschnittlich 12,9 Millionen Dollar pro Jahr durch schlechte Datenqualität. Ein Grossteil davon geht auf fragmentierte, nicht integrierte Datenbestände zurück.
Warum Datenintegration 2026 zum strategischen Thema wird
Datenintegration war immer schon relevant. Aber zwei Entwicklungen machen sie jetzt zum strategischen Thema.
Erstens: KI-Anwendungen brauchen sauberen Kontext. Wer KI-Agenten für Analyse, Recherche oder Reporting einsetzt, muss ihnen vollständige und widerspruchsfreie Daten liefern. Ein LLM, das auf drei verschiedene Versionen eines Kundendatensatzes zugreift, liefert unbrauchbare Ergebnisse. Saubere Datenintegration ist die Voraussetzung dafür, dass Context Engineering überhaupt funktioniert.
Zweitens: Die Anzahl der Datenquellen pro Unternehmen wächst. Jedes neue SaaS-Tool, jede externe Datenquelle, jede API-Anbindung erzeugt einen weiteren Datenstrom, der integriert werden muss. Die Komplexität steigt nicht linear, sondern exponentiell, weil jede neue Quelle mit allen bestehenden Quellen abgeglichen werden muss.
Das Ergebnis: Unternehmen, die Datenintegration als "IT-Projekt" behandeln und einmalig abhandeln wollen, fallen zurück. Integration ist ein laufender Prozess, kein einmaliges Migrationsprojekt.
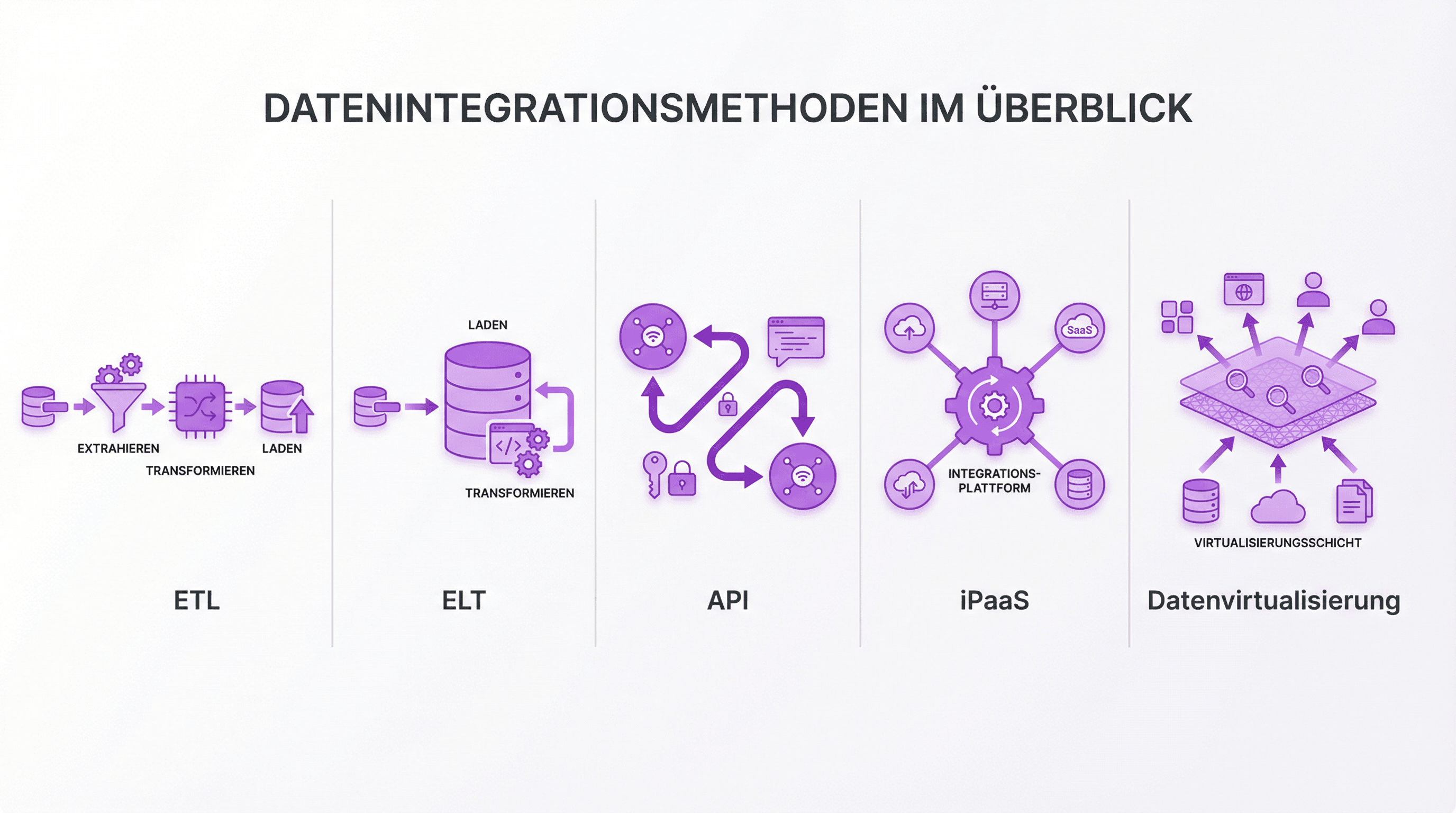
Welche Methoden der Datenintegration gibt es?
Es gibt nicht die eine richtige Methode. Die Wahl hängt davon ab, wie viele Quellen integriert werden, wie aktuell die Daten sein müssen und welche technischen Ressourcen verfügbar sind.
| Methode | Funktionsweise | Geeignet für | Nachteil |
|---|---|---|---|
| ETL (Extract, Transform, Load) | Daten werden aus Quellen extrahiert, in ein Zielformat transformiert und in ein Data Warehouse geladen | Grosse Datenmengen, Batch-Verarbeitung, historische Analysen | Zeitverzug zwischen Extraktion und Verfügbarkeit |
| ELT (Extract, Load, Transform) | Rohdaten werden zuerst geladen, dann im Zielsystem transformiert | Cloud-basierte Architekturen mit leistungsfähigen Zielsystemen | Erfordert starke Rechenkapazität im Zielsystem |
| API-basierte Integration | Systeme tauschen Daten über Schnittstellen in Echtzeit aus | Laufende Synchronisation zwischen wenigen Systemen | Skaliert schlecht bei vielen Quellen |
| Middleware / iPaaS | Eine Integrationsplattform verbindet mehrere Quellen über vorgefertigte Konnektoren | Viele SaaS-Tools, die miteinander sprechen sollen | Abhängigkeit vom Plattformanbieter |
| Datenvirtualisierung | Daten bleiben in den Quellsystemen, werden aber über eine virtuelle Schicht einheitlich abfragbar gemacht | Schneller Zugriff ohne Datenbewegung, exploratives Arbeiten | Kein persistentes Datenmodell, Performance-Limits bei grossen Abfragen |
Die meisten Unternehmen landen am Ende bei einer Kombination. ETL oder ELT für den analytischen Kern, API-basierte Integration für die Echtzeit-Synchronisation operativer Systeme, und Middleware für die Anbindung von Drittanbieter-Tools.
Wo Datenintegration in der Praxis scheitert
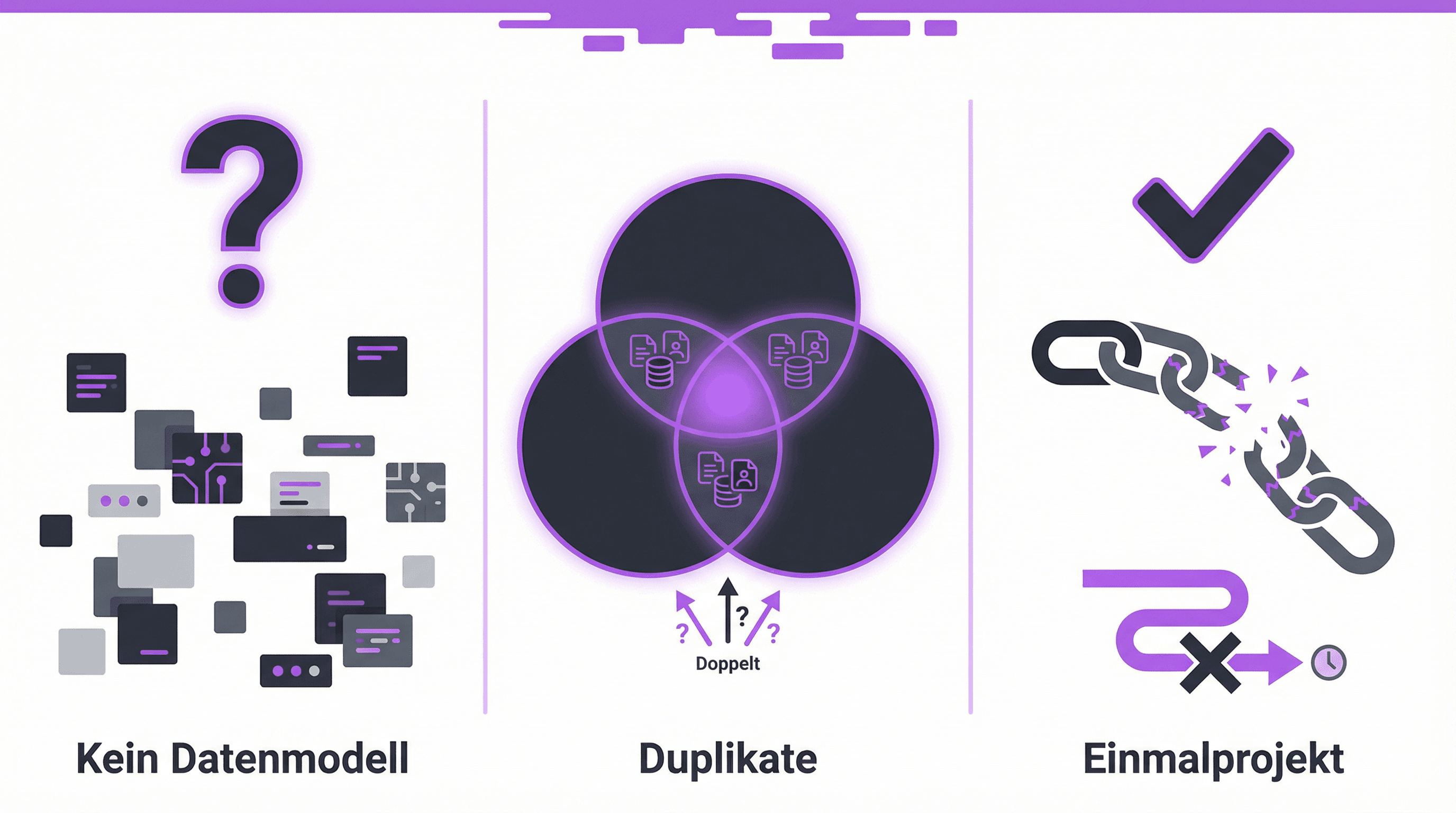
Die Technik ist selten das Problem. Die meisten Integrationsprojekte scheitern an drei Stellen, die wenig mit Technologie zu tun haben.
Kein klares Datenmodell
Teams beginnen mit der Integration, bevor sie definiert haben, was eine "Entität" in ihrem System überhaupt ist. Ist ein Kunde die Person, die unterschrieben hat, oder das Unternehmen? Ist ein Deal das, was im CRM steht, oder das, was tatsächlich verhandelt wird? Ohne diese Grundsatzentscheidungen baut man ein System, das Daten zwar zusammenführt, aber nicht zusammenpassen lässt.
Duplikate werden unterschätzt
Datensilos aufzubrechen und alle Quellen zusammenzuführen klingt nach Fortschritt. Wenn aber dieselbe Entität in drei Systemen mit leicht unterschiedlichen Namen existiert ("Müller AG", "Müller Group", "Mueller AG"), entsteht durch die Integration kein sauberer Datensatz, sondern ein grösseres Chaos. Entity Matching, also die Fähigkeit, Duplikate systemübergreifend zu erkennen, ist die eigentliche Herausforderung. LLM-basierte Ansätze performen hier deutlich besser als klassische regelbasierte Verfahren, weil sie Kontext berücksichtigen statt nur Strings zu vergleichen.
Integration als Einmalprojekt statt als laufenden Prozess
Das grösste Missverständnis: Datenintegration hat einen Anfang und ein Ende. In der Realität ändern sich Quellsysteme, neue Datenfelder kommen hinzu, Anbieter ändern ihre APIs, und die Anforderungen der Nutzer*Innen verschieben sich. Wer Integration nicht als dauerhaften Prozess mit klarer Ownership aufstellt, hat nach sechs Monaten wieder fragmentierte Daten.
Was gute Datenintegration für KI-Anwendungen bedeutet
Der Zusammenhang ist direkt: Die Qualität einer KI-Anwendung ist eine Funktion der Datenqualität. Das gilt für jede Art von KI, aber besonders für LLM-basierte Systeme, die auf Kontext angewiesen sind.
Konkret heisst das:
- Natürlichsprachliche Suche funktioniert nur, wenn alle relevanten Datenquellen in einem Index liegen. Wer fünf Systeme separat durchsuchen muss, bekommt fünf Teilantworten statt einer vollständigen.
- Automatisiertes Scoring von Deals, Startups oder Partnern erfordert, dass alle Datenpunkte an einem Ort zusammenfliessen. Ohne integrierte Datenbasis fehlen dem Modell Signale, und das Scoring wird unzuverlässig.
- KI-gestützte Due Diligence profitiert am stärksten. Agenten, die parallel recherchieren, Datenräume auswerten und strukturierte Ergebnisse liefern, können das nur auf einer vollständigen, integrierten Datenbasis.
- Trigger-basierte Workflows setzen voraus, dass ein Agent ein Ereignis (Finanzierungsrunde, Personalwechsel, neues Patent) mit dem richtigen Kontext verknüpfen kann. Ohne Datenintegration fehlt dieser Kontext.
Die Faustregel, die sich in der Praxis bestätigt: 80% des Aufwands steckt in der Datenaufbereitung, nur 20% in der eigentlichen KI-Anwendung. Wer diesen Schritt überspringt und direkt LLM-basierte Tools auf fragmentierte Quellen loslässt, bekommt vorhersehbar schlechte Ergebnisse.
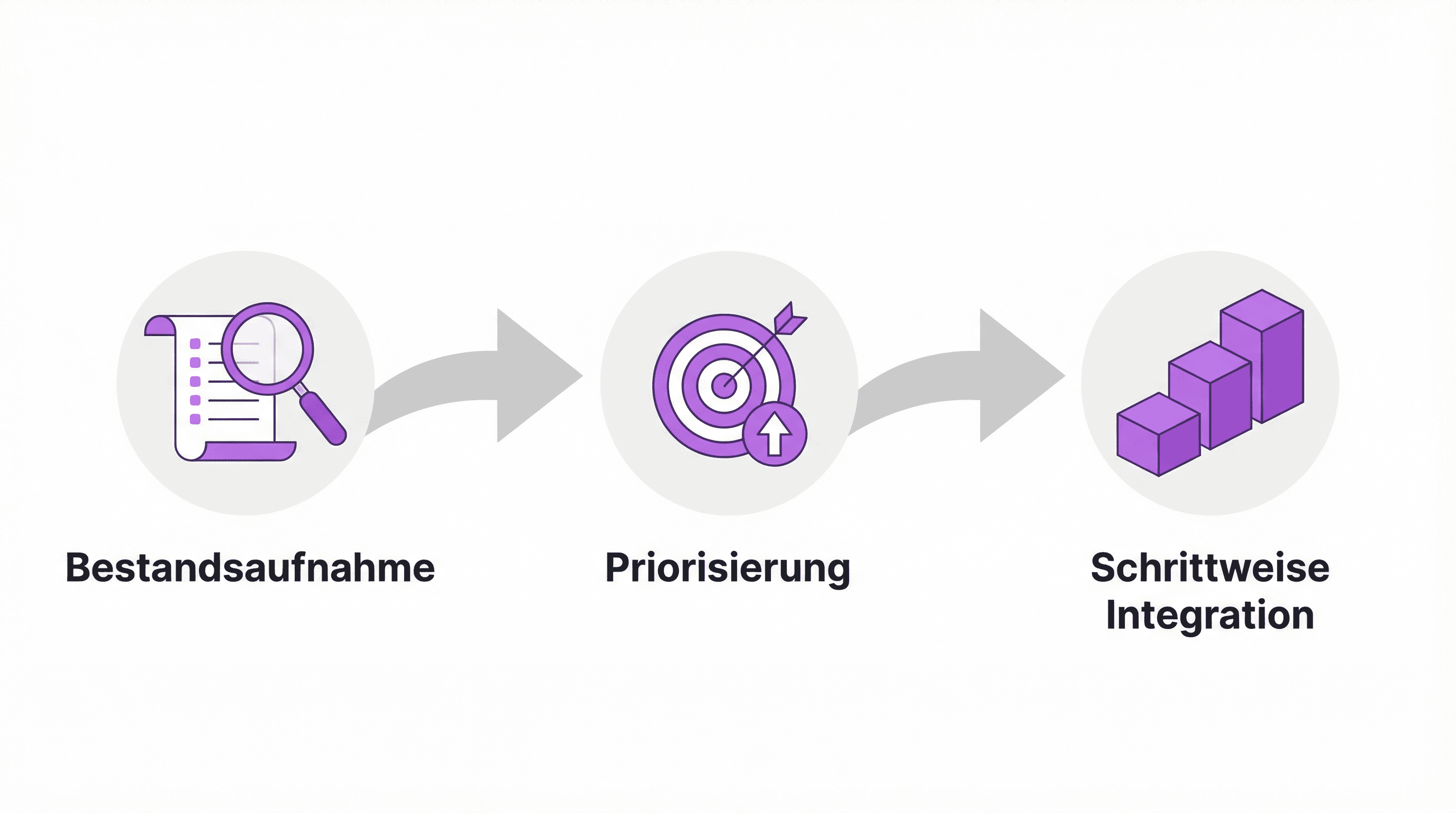
Drei Schritte zur funktionierenden Datenintegration
Wer den Einstieg strukturiert angehen will, braucht keine zwölfmonatige Roadmap. Drei Schritte reichen, um die grössten Hebel zu identifizieren.
Schritt 1: Bestandsaufnahme der Datenquellen. Welche Systeme speichern welche Daten? Wo gibt es Überlappungen? Die meisten Unternehmen kennen nicht einmal die vollständige Liste ihrer aktiven Datenquellen.
Schritt 2: Priorisierung nach Impact. Nicht alle Integrationen sind gleich wertvoll. Die Frage ist: Welche fehlende Verbindung zwischen zwei Systemen verursacht den grössten Zeitverlust oder die meisten Fehler?
Schritt 3: Schrittweise Integration statt Big Bang. Mit zwei oder drei Kernquellen beginnen, messbare Ergebnisse liefern, dann erweitern. Jeder Integrationsschritt muss einen sichtbaren Vorteil bringen, bevor der nächste folgt. Unternehmen, die alles auf einmal lösen wollen, liefern in der Regel nichts.
Wie Researchly Datenintegration für Analyse-Teams löst
Wer Marktdaten, CRM-Einträge, Finanzdaten und interne Dokumente manuell zusammenführt, weiss, wie viel Zeit allein die Bereinigung frisst. Und am Ende sind die Daten trotzdem nicht aktuell.
Researchly automatisiert genau diesen Prozess: Die Plattform integriert strukturierte und unstrukturierte Datenquellen, dedupliziert automatisiert und stellt eine bereinigte Datenbasis bereit, auf der KI-Agenten arbeiten können.
Was das konkret bedeutet:
- Automatisierte Datenintegration: Öffentliche Quellen, CRM-Daten und interne Dokumente fliessen in eine einzige, bereinigte Datenschicht zusammen
- KI-gestützte Extraktion aus unstrukturierten Quellen: PDFs, Berichte und Webquellen werden automatisch in strukturierte, analysierbare Daten umgewandelt
- Agenten, die auf der vollständigen Datenbasis arbeiten: Von automatisiertem Sourcing über Due Diligence bis zum Monitoring auf einer zentralen Plattform