

Early-Stage-Deals (bzw. Early-Stage Startups) werden selten „gefunden“, weil jemand zufällig die Datenbanken wie Crunchbase durchsucht. Sie werden gefunden, weil Teams systematisch Signale aus vielen Quellen sammeln, sie mit klaren Filtern verdichten und dann konsequent nachfassen. Genau hier scheitert klassisches Sourcing oft: zu wenige Datenquellen, zu grobe Filter, zu viel Bauchgefühl.
Dieser Leitfaden zeigt, welche Datenquellen sich für die Suche nach Early Stage Companies eignen, welche Signale wirklich zählen, und wie Sie mit Filtern aus einem riesigen Universum eine belastbare Shortlist bauen.
Was „Early Stage“ in der Praxis bedeutet (und warum das die Suche erschwert)
„Early Stage“ ist kein sauberer Datenbankwert. In der Praxis nutzen Investor:innen und Research-Teams oft Proxy-Definitionen, zum Beispiel:
- Alter: Gründung vor 0 bis 5 Jahren
- Teamgröße: 2 bis 50 Mitarbeitende (je nach Sektor)
- Funding-Proxies: Pre-Seed/Seed, erste institutionelle Runde, oder „noch nicht geraised“
- Produktstatus: MVP bis frühe Skalierung (erste wiederkehrende Umsätze, erste Enterprise-Piloten)
Das Problem: Private Companies publizieren wenig, und viele Signale entstehen außerhalb klassischer Funding-Datenbanken (Hiring, Open Source, Community, Ads, Partnerschaften). Deshalb funktioniert Early-Stage-Discovery am besten über Alternative Data plus ein gutes Filter- und Scoring-System.
Datenquellen für Early Stage Companies: Was wirklich hilft
Statt „die eine perfekte Quelle“ zu suchen, lohnt sich ein Setup aus mehreren Kategorien. Die folgende Übersicht ist bewusst praxisorientiert: Was kommt rein, wofür taugt es, und wo sind die Grenzen.
| Datenquelle | Typische Early-Stage-Signale | Stärke | Grenze / Risiko |
|---|---|---|---|
| LinkedIn (Company Pages, Jobs, People) | Hiring-Tempo, Rollen (Sales vs. R&D), Founder-Hintergrund | Sehr nah an aktueller Realität | Datenqualität schwankt, Begriffe uneinheitlich |
| Job-Boards (z.B. Wellfound) | Neue Stellen, Seniorität, Tech-Stack | Gute Traktions-Proxies | Nicht jede Firma postet öffentlich |
| Produkt-Launch-Plattformen (z.B. Product Hunt) | Launch-Datum, Upvotes, Kommentare, Positionierung | Frühe Produkt- und Community-Signale | Konsumentenlastig, B2B unterrepräsentiert |
| Open Source (z.B. GitHub) | Repo-Aktivität, Stars, Contributor-Wachstum | Starkes Signal bei Developer-Tools | Nicht für jede Branche relevant |
| App Stores | Release-Historie, Updates, Ratings | Nutzungsnähe bei Mobile-first | B2B, Deeptech oft nicht abbildbar |
| Web- und Content-Signale (Blog, Docs, SEO) | Neue Use Cases, Dokumentationstiefe, Traffic-Indizien | Gute Validierung von GTM-Reife | Traffic-Schätzungen sind ungenau |
| Accelerator/Incubator-Demos | Batch-Listen, Teams, oft sehr früh | Hohe Dichte an Early Stage | Selektionsbias (nicht der ganze Markt) |
| Registerdaten (Handelsregister/Unternehmensregister) | Gründungsdatum, Rechtsform, Änderungen | Verlässliche Basisdaten | Wenig Produkt- oder Traktionsinfos |
| Grants, Forschungsnetzwerke, Konferenzen | Projektstarts, Publikationen, Partner | Gut für Deeptech | Längere Zyklen, schwer zu normalisieren |
Nützliche Startpunkte (je nach Mandat und Datenzugang):
- LinkedIn für Team- und Hiring-Signale
- GitHub für Open-Source- und Dev-Tool-Signale
- Product Hunt für Launch- und Community-Signale
- Wellfound (ehemals AngelList Talent) für Early-Stage-Jobs
- Unternehmensregister für Basisdaten in Deutschland oder Firmenbuch für Daten aus Österreich
- Y Combinator Companies (siehe auch Y Combinator Companies finden & tracken: Der komplette Guide für Investoren)
Welche Signale sind stark, welche sind nur „Lärm“?
Viele Teams sammeln Daten, aber bewerten sie falsch. Entscheidend ist, Signale nach Aussagekraft zu priorisieren und sie mit Kontext zu lesen.
Starke Signale (häufig gute Early-Stage-Proxies)
- Hiring mit erkennbarer GTM-Logik: Ein Wechsel von „nur Engineering“ zu „erste Sales/CS/RevOps“-Rollen kann ein gutes Zeichen für Product-Market-Fit-Nähe sein. Umgekehrt kann ein reines Hiring-Feuerwerk auch auf „Runway-Verbrennung“ hindeuten.
- Konsequente Produktiteration: Häufige Releases, Changelogs, wachsende Docs, neue Integrationen. Das deutet auf echte Nutzung und Feedbackschleifen.
- Pull statt Push in der Wahrnehmung: Wiederkehrende Erwähnungen in Communities, Podcasts, technischen Foren oder bei Partnern sind oft belastbarer als einmalige PR.
- Founder-Track-Record und Netzwerk-Pattern: Frühere Gründungen, relevante Domain-Expertise, ungewöhnlich starke Advisor- oder Hiring-Signale.
Schwache Signale (oft überbewertet)
- Follower-Zahlen ohne Engagement: Große Reichweite kann auch reine Creator-Dynamik sein.
- Ein einzelner „Big Logo“-Pilot: Besonders im Enterprise-Bereich sind Piloten häufig explorativ. Wichtiger ist, ob sich daraus Wiederholung ergibt.
- Vanity-PR: „Stealth“, „Revolution“, „Disrupt“ ohne klare Produktbelege.
Ein pragmatischer Ansatz: Bewerten Sie Signale danach, ob sie Verhalten zeigen (Hiring, Releases, Nutzung) statt nur Behauptungen (Brand, PR, Buzzwords).
Filter richtig setzen: Von 200.000 Firmen zu 200 relevanten
Filter sind mehr als „Industrie = Fintech“. Gute Filter bilden Ihre Investment- oder Research-These ab und vermeiden typische Fallen (zu eng, zu weit, falsche Proxies).
Die wichtigsten Filterdimensionen
| Filter | Beispiele | Warum er wirkt | Typische Falle |
|---|---|---|---|
| Stage-Proxies | Gründung < 5 Jahre, Headcount 2 bis 50 | Näherung für „früh“ ohne Funding-Daten | Branchenunterschiede ignorieren (Biotech vs. SaaS) |
| Geo | DACH, EU, „Germany + Remote“ | Rechtliches, Netzwerk, Go-to-Market | Remote-Teams falsch zuordnen |
| Markt/ICP | SMB vs. Enterprise, Buyer Persona | Bessere Vergleichbarkeit im Screening | ICP ist oft nicht explizit beschrieben |
| Tech-/Produktkategorie | „LLM Ops“, „Warehouse Automation“ | Präziser als breite Sektoren | Taxonomie wird schnell veraltet |
| Traktions-Proxies | Hiring-Pattern, Release-Frequenz | Bewertet Momentum | Momentum kann kurzfristig sein |
| Intent-Signale | „Pricing“-Seite, Case Studies, Security-Seiten | Indiz für Sales-Reife | Manche Firmen verstecken Pricing bewusst |
Ein praktisches Filter-Framework (das Teams wirklich nutzen)
Gefundene Startups sofort bewerten mit dem → VC Scorecard
- Erst breit, dann scharf: Starten Sie mit wenigen harten Filtern (Geo, Stage-Proxies) und lassen Sie die Quellen „atmen“. Zu frühe Engführung reduziert serendipity.
- Taxonomie über Keywords: Keywords allein sind fragil. Besser ist eine Taxonomie, die Synonyme, benachbarte Kategorien und Ausschlüsse abbildet (zum Beispiel „Fraud“ vs. „KYC“ vs. „AML“, plus Ausschluss „Crypto Exchange“, falls nicht relevant).
- Ausschlussfilter explizit machen: Viele Shortlists werden schlechter, weil Ausschlüsse fehlen (z.B. Agenturen, Beratungen, reine Communities, Holding-Strukturen).
- Scoring statt „Ja/Nein“: Nutzen Sie Filter für ein Grundrauschen, aber priorisieren Sie anschließend per Score (Founder, Signalstärke, Marktfit).
Diese Framework hilft Ihnen anschließen auch Ihr Due Diligence mit KI zu beschleunigen.
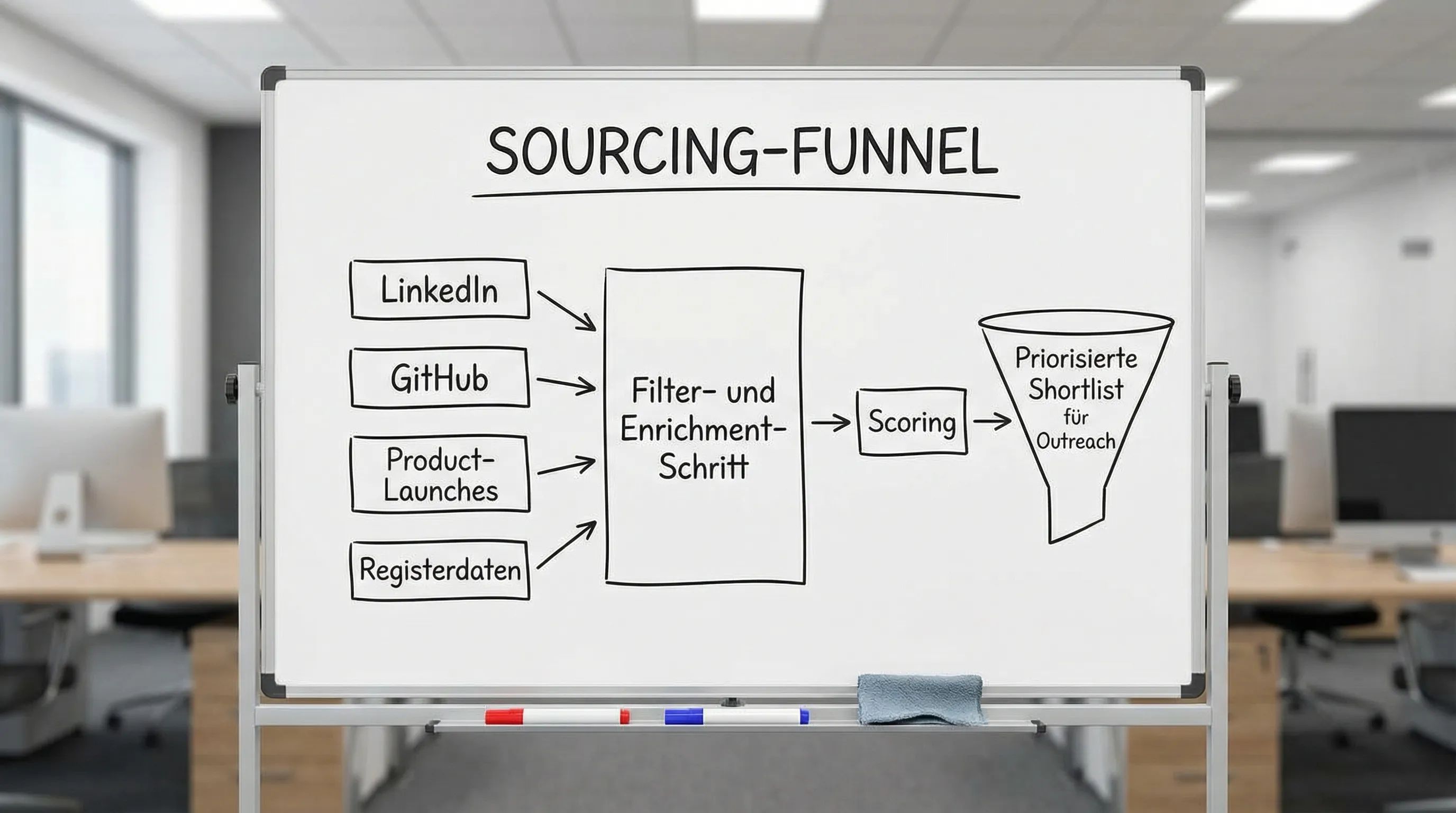
Ein Workflow, der Datenquellen und Filter sauber zusammenbringt
In leistungsfähigen Sourcing-Teams trennt sich „Daten sammeln“ von „Entscheidungen treffen“. Ein robuster Workflow sieht typischerweise so aus:
Thesis und Suchraum operationalisieren
Definieren Sie Ihre Suchhypothese so, dass sie filterbar wird: Markt, Buyer, Preislogik, Integrationen, Regulatorik, Geo. Je klarer diese Kriterien, desto weniger Zeit verlieren Sie später in Debatten.
Quellen kombinieren, dann deduplizieren
Mehrere Quellen führen fast immer zu Duplikaten (Namensvarianten, neue Domains, Rebrands). Planen Sie Deduplikation als festen Schritt ein, bevor Sie „spannend“ markieren.
Enrichment: Kontext schaffen, bevor Sie bewerten
Schnelles Enrichment pro Company (Website, Team, Produkt, Kategorie, Stage-Proxies, relevante Signale) verhindert, dass Analyst:innen die falschen Dinge vergleichen.
Scoring und Routing
Nicht jede Firma muss sofort ein Deal werden. In der Praxis helfen drei Output-Kanäle:
- Now: passt in die Pipeline (Outreach, Intro, Meeting)
- Watch: Signal Feed beobachten (Hiring, Releases, Runde)
- Pass: dokumentierter Grund (hilft später bei Konsistenz)
Typische Fehler beim Finden von Early Stage Companies
Zu stark auf Funding-Datenbanken verlassen
Funding-Daten sind wertvoll, aber oft zu spät für echtes Early Stage Alpha. Viele der interessantesten Teams tauchen zuerst über Hiring, Produkt-Iteration oder Community-Signale auf.
Filter nach „Industrie“ statt nach Buyer und Problem
„Cybersecurity“ ist kein Markt, sondern ein Dach. Suchen Sie lieber nach Problemräumen und Buyer-Kontext (z.B. „Cloud Security für DevOps“, „Identity für B2B SaaS“, „OT Security für Manufacturing“).
Signale ohne Zeitachse bewerten
Ein Snapshot ist gefährlich. Achten Sie auf Veränderung: wächst das Team, steigt die Release-Frequenz, werden Case Studies konkreter? Momentum ist oft wichtiger als absolute Werte.
Outreach ohne saubere Segmentierung
Early Stage Founders reagieren anders als Series-A-Teams. Segmentieren Sie mindestens nach Stage-Proxies und Produktreife, sonst verpuffen selbst gute Listen.
Compliance und Datenethik ignorieren
Gerade in der EU sollten Teams Datennutzung, Scraping-Regeln, und DSGVO-Kontext sauber prüfen. „Weil es technisch geht“ ist keine Strategie. Organisieren Sie Workflows so, dass Quellen, Nutzungsrechte und Opt-out-Logik transparent sind.
Wie Reseachly beim Finden und Filtern von Early Stage Companies unterstützt
Wenn Sie die oben beschriebenen Schritte regelmäßig machen, entstehen schnell zwei Engpässe: (1) zu viele Quellen, (2) zu viel manuelle Arbeit für Enrichment, Deduplikation und Priorisierung.
Reseachly ist dafür gebaut, Sourcing- und Research-Teams zu entlasten, indem es AI-getriebene Startup-Discovery mit präzisen Suchfiltern und automatisierten Workflows kombiniert. Aus den bereitgestellten Produktinformationen sind besonders relevant für dieses Thema:
- Startup Discover mit KI und Market Mapping , um Suchräume strukturierter aufzubauen
- Firmenspezifische, täglich aktualisierte Signals, damit Watchlists nicht veralten
- Dynamische Filter, um schneller von „Universum“ zur Shortlist zu kommen
- Konkurrenzsuche und Benchmarking, um Vergleiche, Due Diligence und Priorisierung zu beschleunigen
Wenn Sie gerade dabei sind, Ihr Sourcing auf alternative Datenquellen umzustellen oder Ihre Filterlogik zu professionalisieren, ist das der naheliegende nächste Schritt: ein Setup, das Discovery, Signale und Workflow zusammenführt.
Mehr dazu auf Researchly