

Semantic Layer — Was ist das und warum braucht Ihr Unternehmen einen?
Statt SUM(revenue) GROUP BY customer_id einfach fragen: "Umsatz pro Kunde im Q3." Ein Semantic Layer macht genau das möglich. Er übersetzt die technische Struktur Ihrer Datenbank in Begriffe, die Fachabteilungen verstehen. Das ist die Grundlage für Self-Service BI und KI-gestützte Analysen.
Was ein Semantic Layer wirklich ist
Ein Semantic Layer ist eine logische Schicht zwischen Ihrer Datenbank und den Menschen (oder KI-Systemen), die mit den Daten arbeiten. Er definiert, was technische Datenfelder im Business-Kontext bedeuten.
Konkret: Ihre Datenbank hat eine Tabelle trx_hist mit einer Spalte amt_net. Kein Mensch außerhalb des Data Teams weiß, was das bedeutet. Ein Semantic Layer übersetzt das in "Nettoumsatz" und legt fest, wie dieser berechnet wird, welche Filter gelten und welche Zeiträume relevant sind.
Das Konzept existiert seit 1992, als Business Objects ein Patent auf die Idee anmeldete, Endanwender*Innen ohne SQL-Kenntnisse auf relationale Datenbanken zugreifen zu lassen. Die Technologie hat sich seitdem verändert, aber die Grundidee ist geblieben: technische Daten in Business-Sprache übersetzen.
Der Unterschied zu einem Dashboard: Ein Dashboard zeigt vordefinierte Ansichten. Ein Semantic Layer ermöglicht es, neue Fragen an die Daten zu stellen, ohne dass jemand eine neue Abfrage programmieren muss.
Semantic Layer vs. Data Warehouse vs. ETL vs. Data Mart
Die Begriffe werden oft verwechselt. Hier die Abgrenzung:
| Konzept | Was es tut | Metapher |
|---|---|---|
| ETL | Extrahiert Daten aus Quellsystemen, transformiert sie und lädt sie in ein Zielsystem | Die Spedition, die Waren ins Lager bringt |
| Data Warehouse | Speichert strukturierte Daten zentral und optimiert für Abfragen | Das Lager selbst |
| Data Mart | Ein Ausschnitt des Data Warehouse für eine bestimmte Abteilung (z.B. Vertrieb) | Ein Regal im Lager, sortiert nach Thema |
| Semantic Layer | Definiert, was die gespeicherten Daten im Business-Kontext bedeuten | Das Etikett auf jedem Produkt im Regal |
Das Data Warehouse beantwortet die Frage "Wo liegen die Daten?". Der Semantic Layer klärt "Was bedeuten die Daten?". Beides ist nötig, aber die meisten Unternehmen investieren massiv in Ersteres und ignorieren Letzteres.
Das Ergebnis kennt jeder, der mit Datensilos zu tun hat: Die Daten liegen sauber im Warehouse, aber jede Abteilung rechnet "Umsatz" anders. Finance zählt gebuchten Umsatz nach Retouren. Marketing zählt Brutto-Transaktionsvolumen. Und das KI-Tool rechnet das, was es in den Rohdaten findet, inklusive Testdaten und ohne klare Definition.
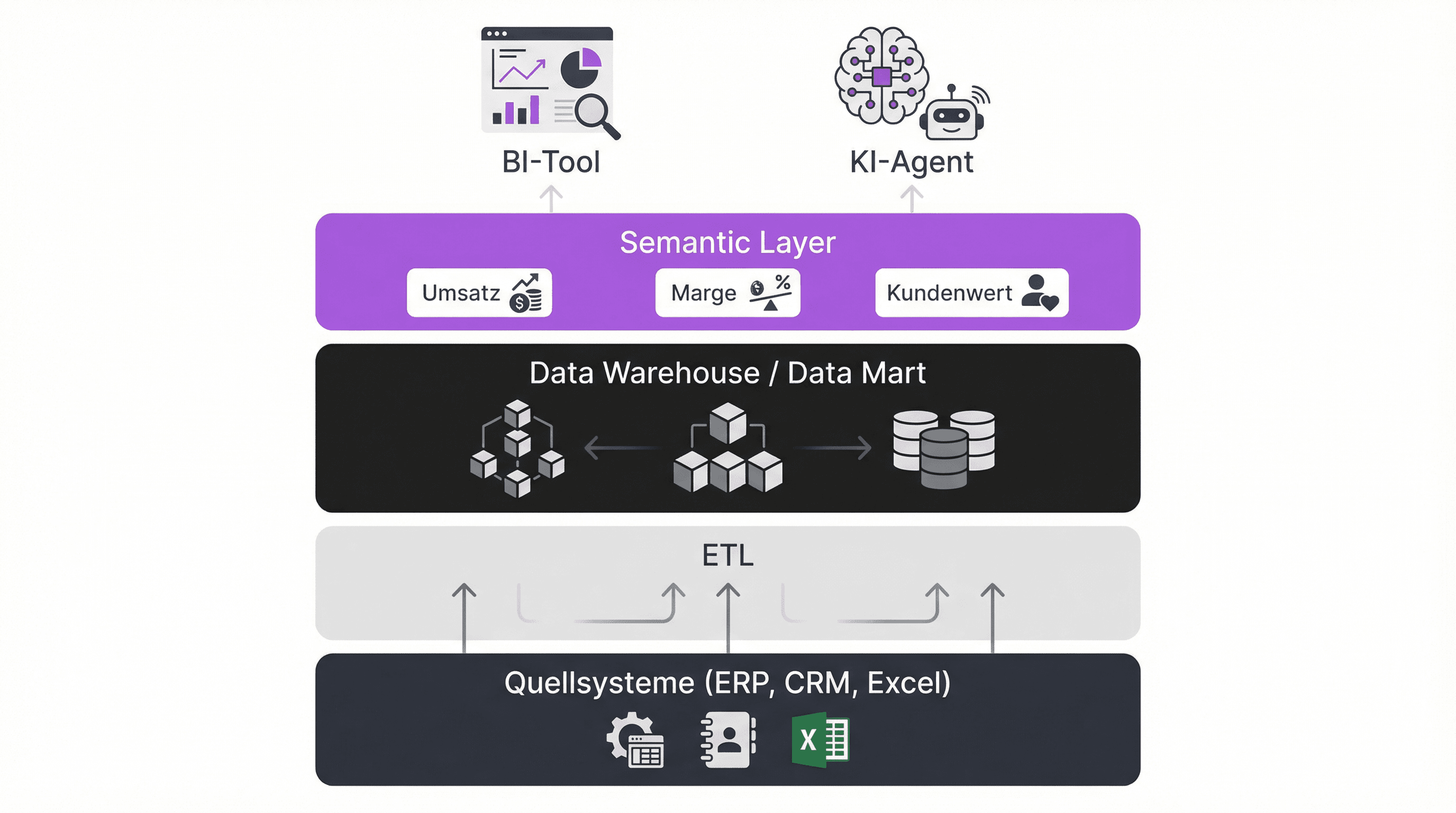
Warum KI-Tools ohne Semantic Layer scheitern
Ein LLM wie ChatGPT oder ein KI-Copilot versteht keine Datenbankschemata. Wenn Sie einem KI-Agenten die Frage "Wie hoch war unser Umsatz letztes Quartal?" stellen, passiert Folgendes:
- Der Agent findet drei Tabellen, die etwas mit Revenue zu tun haben
- Jede hat eine andere Berechnungslogik
- Der Agent wählt eine davon, ohne zu wissen, welche die richtige ist
- Sie bekommen eine Zahl, die vielleicht stimmt. Oder auch nicht.
Laut einer Analyse von AtScale zeigen 95% der generativen KI-Pilotprojekte keinen messbaren Geschäftseffekt. Ein Hauptgrund: Die Datenbasis ist nicht bereit. Gartner prognostiziert, dass über 40% der Agentic-AI-Projekte bis 2027 eingestellt werden, weil die Datengrundlage fehlt.
Ein Semantic Layer löst dieses Problem an der Wurzel. Er gibt dem KI-System den Business-Kontext mit: "Umsatz" bedeutet in unserem Unternehmen X, berechnet als Y, gefiltert nach Z. Das LLM fragt nicht mehr die Rohtabellen ab, sondern arbeitet mit definierten, verlässlichen Metriken.
Für Unternehmen, die bereits ihre zentrale Datenbasis geschaffen haben, ist der Semantic Layer der logische nächste Schritt: von "Daten an einem Ort" zu "Daten, die jeder versteht". Wer schon eine Bilanzanalyse mit KI ausprobiert hat, kennt das Problem: Die Rohdaten allein reichen nicht. Ohne Kontext halluziniert das Modell.
Woraus ein Semantic Layer besteht
Ein Semantic Layer besteht im Kern aus vier Komponenten, die zusammenspielen.
Metadaten bilden das Fundament. Sie beschreiben, woher ein Datenfeld kommt, wann es zuletzt aktualisiert wurde und wer die Definition verantwortet. Wenn eine Metrik wie "Kundenwert" in einem Report auftaucht, liefern die Metadaten den Kontext: welche Quellsysteme einfließen, welche Einschränkungen gelten und wie aktuell die Zahl ist.
Business-Logik definiert die eigentlichen Berechnungen. Hier wird festgelegt, dass "Bruttomarge" Umsatz minus Herstellkosten bedeutet, bereinigt um Retouren und Rabatte. Diese Logik wird einmal definiert und gilt für alle Tools und alle Nutzer*Innen. Ändert sich die Berechnungsformel, wird sie an einer Stelle angepasst, und alle Reports ziehen automatisch nach.
Zugriffskontrolle regelt, wer welche Daten sehen darf. Eine VertriebsleiterIn sieht die Umsatzdaten der eigenen Region, aber nicht die konzernweite Marge. Diese Regeln sind Teil des Semantic Layer und werden automatisch bei jeder Abfrage angewendet.
Caching sorgt für Geschwindigkeit. Häufig abgefragte Metriken wie der Monatsumsatz pro Region werden zwischengespeichert, statt bei jedem Aufruf neu berechnet. Das ist dann relevant, wenn mehrere BI-Tools und KI-Agenten gleichzeitig auf den Semantic Layer zugreifen.
Praxisbeispiel: Vom ERP-Dump zur Business-Frage
Nehmen wir ein mittelständisches Fertigungsunternehmen mit 200 Mitarbeitenden. Die Daten liegen in SAP (ERP), Salesforce (CRM) und diversen Excel-Dateien. Der Controller braucht jeden Montag zwei Stunden, um die Umsatzzahlen manuell zusammenzutragen und abzugleichen.
Ohne Semantic Layer: Der Controller exportiert Daten aus SAP, verknüpft sie manuell mit CRM-Daten in Excel, korrigiert Abweichungen und erstellt den Report. Fragt der Geschäftsführer spontan nach den Top-10-Kunden nach Deckungsbeitrag, dauert die Antwort Tage.
Mit Semantic Layer: Die Metriken "Umsatz", "Deckungsbeitrag" und "Kundengruppe" sind einmal definiert und mit den Quellsystemen verknüpft. Der Controller öffnet das BI-Tool und sieht die aktuellen Zahlen. Oder der Geschäftsführer fragt den KI-Assistenten: "Top-10-Kunden nach Deckungsbeitrag, Q4 2025." Die Antwort kommt in Sekunden und basiert auf derselben Berechnungslogik wie der offizielle Monatsreport.
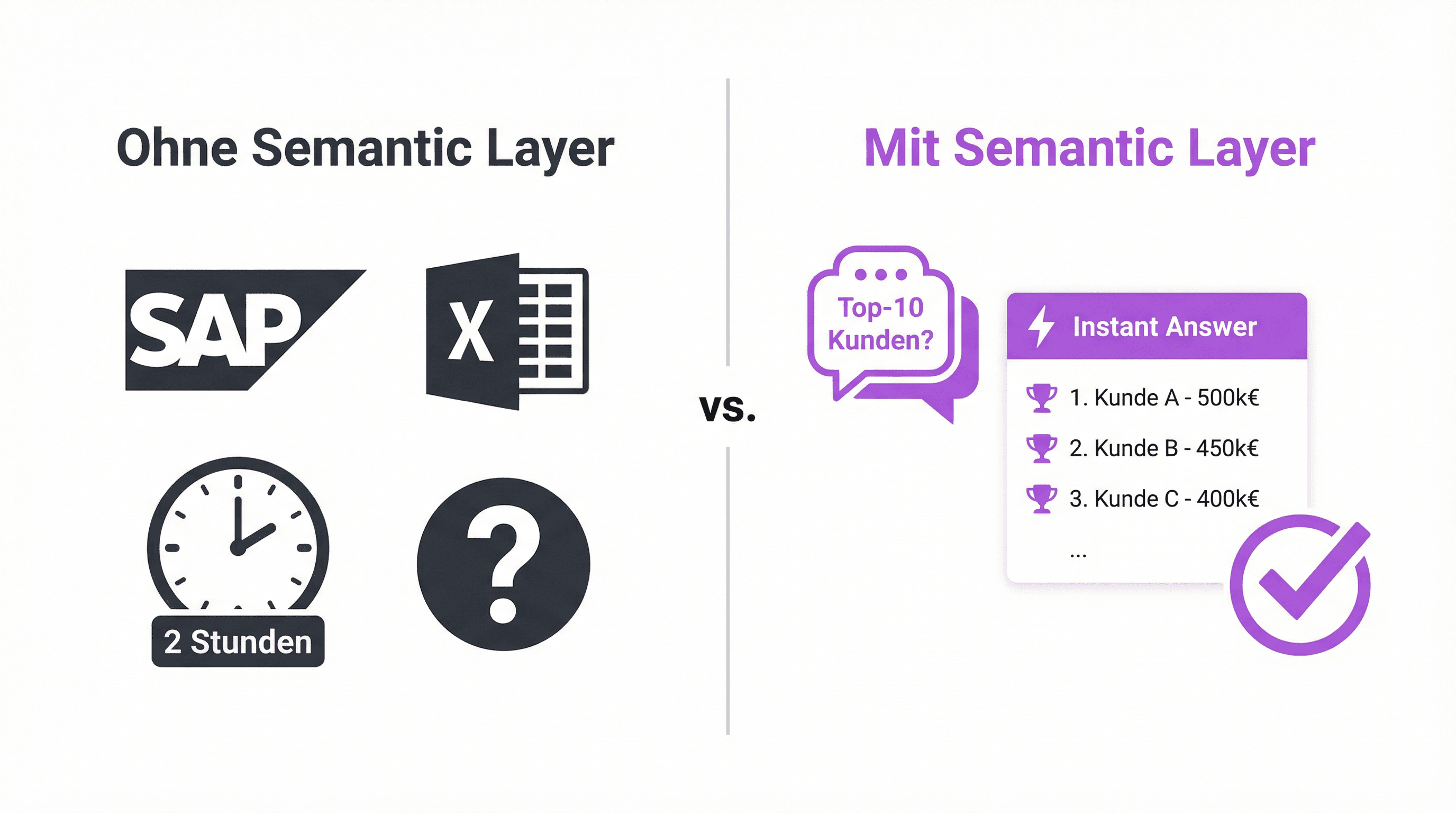 Der eigentliche Gewinn ist nicht die Geschwindigkeit, sondern das Vertrauen. Wenn alle Abteilungen mit denselben Definitionen arbeiten, verschwinden die Abstimmungsmeetings, in denen darüber diskutiert wird, wessen Zahlen stimmen. Wer das im Finanzbereich erlebt hat, weiß, wie viel Zeit das frisst.
Der eigentliche Gewinn ist nicht die Geschwindigkeit, sondern das Vertrauen. Wenn alle Abteilungen mit denselben Definitionen arbeiten, verschwinden die Abstimmungsmeetings, in denen darüber diskutiert wird, wessen Zahlen stimmen. Wer das im Finanzbereich erlebt hat, weiß, wie viel Zeit das frisst.
Die wichtigsten Semantic Layer Tools
Der Markt teilt sich in zwei Kategorien: BI-native Semantic Layer (eingebaut in ein bestimmtes BI-Tool) und universelle Semantic Layer (unabhängig von einem einzelnen Tool).
| Tool | Typ | Stärke | Einschränkung |
|---|---|---|---|
| dbt Semantic Layer | Universell (Cloud) | Open Source, MetricFlow-Engine, Git-basiert | Nur in dbt Cloud verfügbar |
| Looker / LookML | BI-nativ (Google) | Starkes Datenmodell, gute Governance | An Google-Ökosystem gebunden |
| Power BI Semantic Model | BI-nativ (Microsoft) | Breite Verbreitung, Excel-Integration | Begrenzt auf Microsoft-Stack |
| AtScale | Universell | Plattformunabhängig, AI-ready | Enterprise-Preismodell |
| Cube | Universell (API-first) | Entwicklerfreundlich, headless | Technisches Setup nötig |
| Denodo | Datenvirtualisierung | Kein Daten-Kopieren nötig | Komplexe Lizenzierung |
Für mittelständische Unternehmen, die bereits Power BI oder Looker nutzen, ist der BI-native Ansatz oft der pragmatische Einstieg. Wer mehrere BI-Tools im Einsatz hat oder KI-gestützte Datenanalysen anbinden will, braucht einen universellen Semantic Layer. Die Entscheidung beim Vergleich der Plattformen hängt weniger von Features ab als von einer einfachen Frage: Nutzen Sie ein einziges BI-Tool oder mehrere?
Bei einem Tool reicht der eingebaute Semantic Layer. Bei mehreren brauchen Sie eine plattformunabhängige Lösung, damit "Umsatz" überall dasselbe bedeutet.
Wie Sie einen Semantic Layer aufbauen
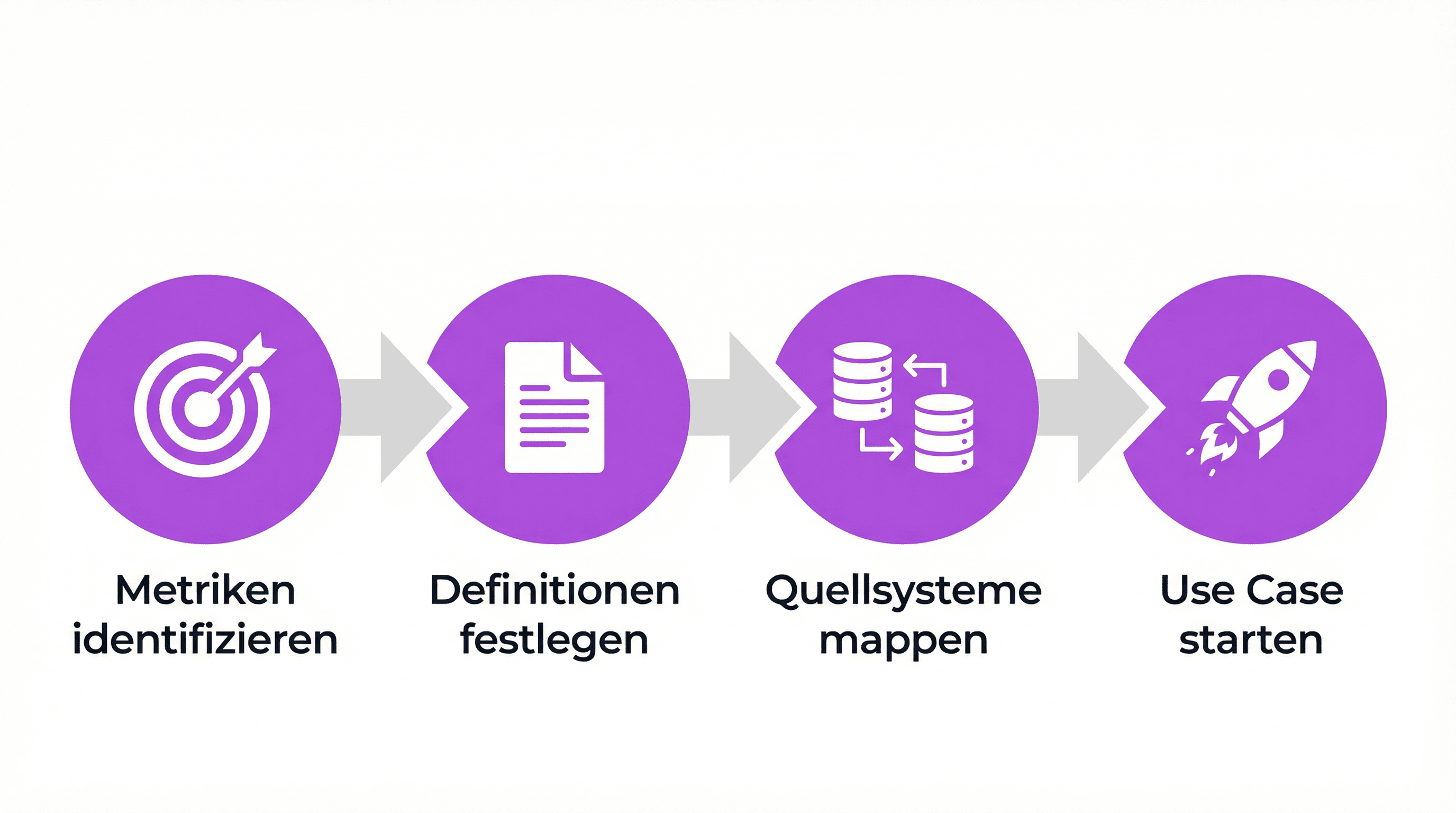
Der Aufbau muss kein Mammutprojekt sein. Vier Schritte reichen für den Einstieg:
1. Die wichtigsten Metriken identifizieren. Nicht 500 KPIs definieren, sondern die 10-15 Kennzahlen, über die in Meetings gestritten wird. Umsatz, Marge, Kundenwert, Churn-Rate. Die Metriken, bei denen verschiedene Abteilungen unterschiedliche Zahlen liefern.
2. Einheitliche Definitionen festlegen. Für jede Metrik dokumentieren: Wie wird sie berechnet? Welche Filter gelten? Welche Datenquellen fließen ein? Das klingt banal, wird in der Praxis aber fast nie gemacht. Genau hier entsteht der Wert.
3. Auf Quellsysteme mappen. Jede Definition mit den tatsächlichen Datenbankfeldern verknüpfen. Das erfordert die Zusammenarbeit von Fachbereich und Data Team. Der Fachbereich weiß, was die Metrik bedeuten soll. Das Data Team weiß, wo die Daten liegen. Ohne beide Seiten funktioniert es nicht.
4. Mit einem Use Case starten. Nicht den gesamten Semantic Layer auf einmal aufbauen, sondern mit einem konkreten Anwendungsfall beginnen, etwa dem monatlichen Vertriebsreport. Dort den Nutzen beweisen und dann schrittweise erweitern. BeraterInnen und AnalystInnen, die bereits KI-gestützt arbeiten, kennen dieses Vorgehen: klein starten, schnell Ergebnisse zeigen, dann skalieren.
 Unternehmen, die Erfahrung mit Data Governance und Datenqualität haben, sind im Vorteil. Die organisatorische Vorarbeit ist oft schon geleistet. Was fehlt, ist die technische Umsetzung.
Unternehmen, die Erfahrung mit Data Governance und Datenqualität haben, sind im Vorteil. Die organisatorische Vorarbeit ist oft schon geleistet. Was fehlt, ist die technische Umsetzung.
Der Semantic Layer wird Pflicht, nicht Kür
Die Frage ist nicht mehr, ob ein Unternehmen einen Semantic Layer braucht, sondern wann es einen aufbaut. Mit jedem KI-Tool, das an Unternehmensdaten angebunden wird, steigt das Risiko inkonsistenter Ergebnisse. Und mit jedem Abstimmungsmeeting, in dem drei Abteilungen drei verschiedene Umsatzzahlen präsentieren, steigt der Leidensdruck.
Wer jetzt die Grundlagen schafft, hat einen Vorsprung. Nicht weil der Semantic Layer selbst ein Wettbewerbsvorteil ist, sondern weil er die Voraussetzung dafür ist, dass KI-gestützte Analysen in Ihrem Unternehmen tatsächlich funktionieren.
So unterstützt Researchly KI-gestützte Analysen
Die meisten Unternehmen scheitern nicht an der KI selbst, sondern an der Datenbasis. Wenn Ihre Daten in verschiedenen Systemen liegen und jede Abteilung eigene Definitionen nutzt, liefern KI-Tools keine verlässlichen Ergebnisse.
Researchly hilft Teams dabei, dieses Problem zu lösen:
- Automatisierte Datenrecherche über fragmentierte Quellen hinweg, mit konsistenten Analyseergebnissen
- KI-Agenten für strukturierte Analysen, die auf definierten Frameworks arbeiten statt auf Rohdaten
- Zentrale Plattform statt 20 Einzeltools, damit Ihre Analysen auf derselben Datenbasis aufbauen