

Wenn Teams heute von „AI for Data Analysis“ sprechen, meinen sie oft sehr unterschiedliche Dinge: klassische ML-Modelle für Forecasting, LLMs für Text- und Dokumentenanalyse, oder hybride Ansätze (zum Beispiel Retrieval-Augmented Generation) für research-intensives Arbeiten. Gemeinsam ist allen Varianten: Sobald Ergebnisse entscheidungsrelevant werden (Investment Committee, Vorstand, Kundenpräsentation, Audit), reichen Geschwindigkeit und „gefühlte Intelligenz“ nicht mehr aus.
Was dann zählt, sind Governance, Datenqualität und Explainability (Erklärbarkeit). Diese drei Disziplinen entscheiden, ob KI-gestützte Analysen in PE, VC, Consulting und Corporate Strategy als belastbar gelten oder als Black Box scheitern.
1) Governance: Wer trägt Verantwortung, wofür und mit welchen Leitplanken?
Governance ist das Betriebssystem für KI in der Analyse. Sie schafft Zuständigkeiten, Risiko-Kontrollen und Nachvollziehbarkeit, bevor ein Modell überhaupt produktiv geht.
Governance beginnt mit einer präzisen Systemdefinition
Viele Governance-Probleme entstehen, weil nicht sauber definiert ist, was das KI-System eigentlich ist:
- Welche Datenquellen fließen ein (intern, extern, lizenzpflichtig, öffentlich)?
- Welche Aufgaben werden automatisiert (Klassifikation, Summaries, KPI-Extraktion, Benchmarking, Empfehlungen)?
- Welche Nutzergruppen treffen damit Entscheidungen (Analysten, Partner, Investment Team, Compliance)?
- Was ist der „Decision Impact“ (informativ vs. entscheidungssteuernd)?
Diese Abgrenzung ist zentral, weil sich daraus Risikoklasse, Prüfpflichten und Freigabeprozesse ableiten.
Ein praxistaugliches Governance-Modell (ohne Overhead)
Ein gutes Zielbild ist: so viel Governance wie nötig, so wenig wie möglich. In der Praxis bewährt sich ein schlankes Modell mit klaren Rollen:
- Business Owner (z. B. Head of Research / Deal Team Lead): verantwortlich für Zweck, Nutzen, Akzeptanzkriterien.
- Data Owner (z. B. Finance/Data Office): verantwortlich für Datenfreigaben, Datenverträge, Quality SLAs.
- Model Owner (Analytics/AI Lead): verantwortlich für Modellwahl, Tests, Drift-Monitoring, Dokumentation.
- Risk/Compliance: verantwortet Policy, Auditfähigkeit, regulatorische Anforderungen.
- Security: verantwortet Zugriff, Verschlüsselung, Third-Party-Risiken.
Wichtig: „Alle sind zuständig“ ist in der Realität „niemand ist zuständig“. Governance muss Verantwortlichkeit explizit machen.
Ankerpunkte aus Standards und Regulierung
Ohne in Formalismus zu kippen, lohnt es sich, Governance an etablierten Rahmenwerken auszurichten:
- NIST AI Risk Management Framework (AI RMF 1.0): sehr praxisnah für Risikoidentifikation, Controls und kontinuierliche Steuerung.
- ISO/IEC 42001 (AI Management System): Managementsystem-Ansatz, hilfreich für größere Organisationen.
- EU AI Act: relevant, sobald KI-Systeme in der EU betrieben werden und (je nach Use Case) Anforderungen an Transparenz, Risikomanagement und Dokumentation greifen.
Für Data-Analysis-Use-Cases in Investment- und Strategiekontexten sind besonders wichtig: Nachvollziehbarkeit, Zugriffskontrolle, Third-Party-Governance, sowie klare Regeln für „Human-in-the-loop“.
Governance-Artefakte, die wirklich helfen
Statt dicker Policy-Ordner funktionieren wenige, gut gepflegte Artefakte:
| Governance-Artefakt | Zweck | Wer nutzt es | Typischer Umfang |
|---|---|---|---|
| Use-Case-Canvas (Zweck, Scope, Impact) | Klarheit über Entscheidungskontext und Risiko | Business, Risk | 1 Seite |
| Data Source Register (inkl. Lizenz, Aktualität) | Quellenhygiene, Auditfähigkeit | Data, Compliance | laufend |
| Model Card / System Card | Grenzen, Tests, Annahmen, bekannte Risiken | Analytics, Audit | 1 bis 3 Seiten |
| Prompt/Workflow Change Log (bei LLMs) | Reproduzierbarkeit, Root Cause Analyse | AI Team | laufend |
| Freigabeprozess mit Stufen (Pilot, Limited, Prod) | kontrollierter Rollout | Alle | Prozess |
Gerade bei LLM-basierten Analyse-Workflows ist ein Change Log entscheidend: Schon kleine Prompt-Änderungen können Outputs signifikant verändern.
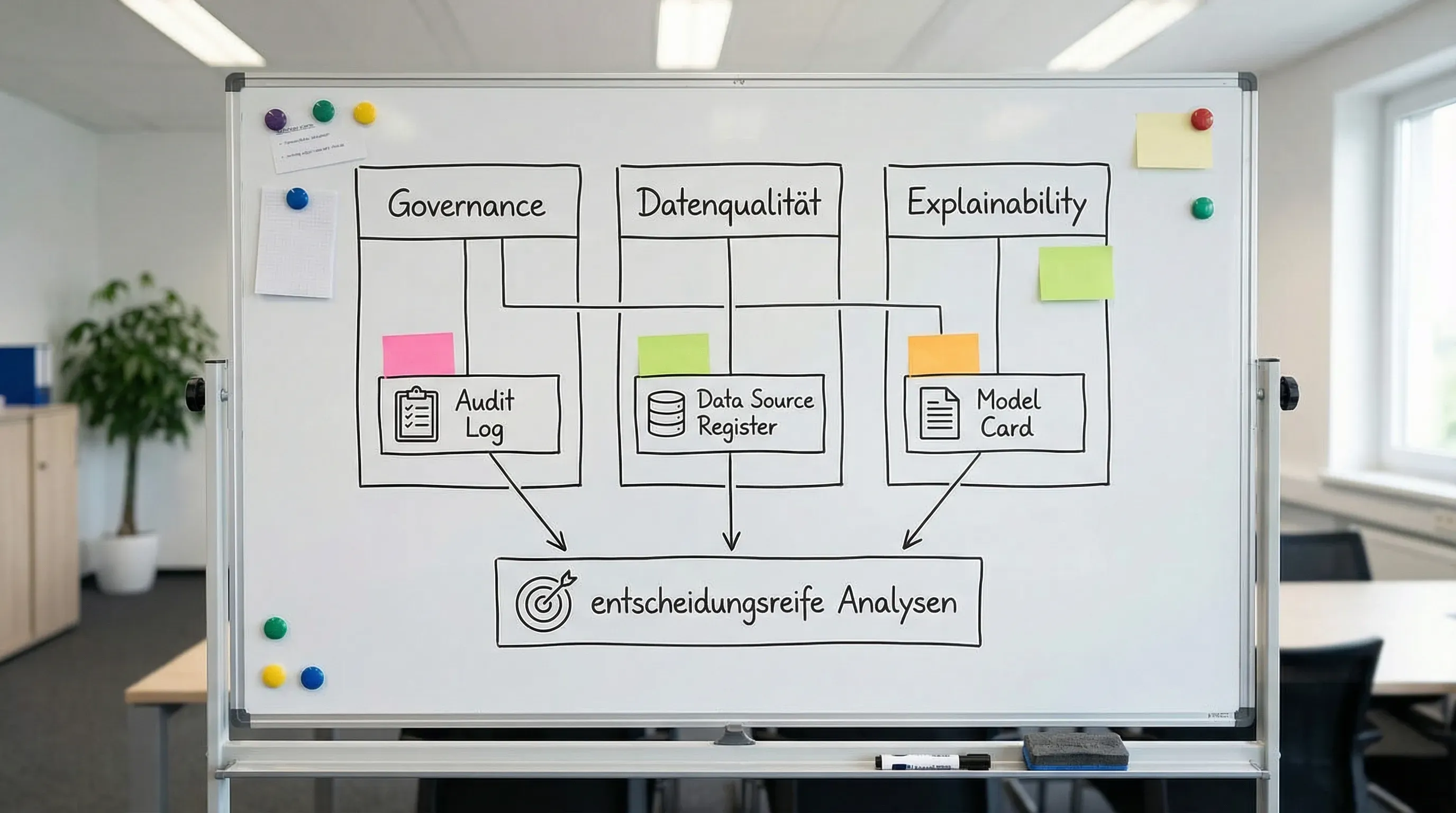
2) Datenqualität: „Garbage in“ wird mit KI nur schneller
KI kann schlechte Daten nicht „wegzaubern“. In vielen Organisationen verstärkt AI for Data Analysis sogar das Problem: Ergebnisse wirken überzeugend formuliert, sind aber auf unsauberem Datenfundament gebaut.
Datenqualität ist mehrdimensional
Klassische Qualitätsdimensionen (angelehnt an gängige Data-Management-Praktiken) sind:
- Accuracy: stimmt der Wert mit der Realität überein?
- Completeness: fehlen Felder, Zeitreihen, Dokumente?
- Consistency: sind Definitionen über Quellen hinweg einheitlich?
- Timeliness: ist die Information aktuell genug für die Entscheidung?
- Lineage: lässt sich nachvollziehen, woher ein Wert stammt?
In Deal- und Strategy-Analysen kommt eine zusätzliche Dimension hinzu: „Provenance“ (Herkunft) und Lizenz der Quellen, besonders bei externen Daten.
Spezifische Qualitätsrisiken bei LLM-gestützter Analyse
LLMs bringen eigene Failure-Modes mit, die klassisches BI nicht kennt:
- Halluzinationen: plausibel klingende, aber nicht belegte Aussagen.
- Citation Gaps: Aussagen ohne belastbare Quelle, oder Quellen, die den Claim nicht tragen.
- Context Leakage: irrelevante Dokumente beeinflussen die Antwort.
- Stille Unschärfe: Zahlen werden gerundet oder implizit interpretiert, ohne Kennzeichnung.
Die Konsequenz: Datenqualität muss bei LLM-Systemen um Grounding-Qualität erweitert werden.
Qualitätskontrollen, die in der Praxis funktionieren
Für research-nahe Datenanalyse (Reports, Due Diligence, Markt- und Wettbewerbsbilder) funktionieren diese Kontrollen besonders gut:
1) Quellen- und Dokumenten-Gates Bevor ein System Antworten generiert, sollte klar sein:
- Welche Quellen sind erlaubt (Whitelists)?
- Welche Quelle ist für welche Aussageklasse zulässig (z. B. regulatorische Aussagen nur aus Primärquellen)?
- Wie wird Aktualität gesichert (z. B. „nicht älter als X Monate“ bei Marktkennzahlen)?
2) Strukturierte Extraktion statt reinem Free-Text Wo immer möglich, sollten Kerndaten als strukturierte Felder extrahiert und validiert werden (z. B. Umsatz, EBITDA-Definition, Segmentumsätze, Headcount, Pricing-Logik). Das reduziert Interpretationsspielraum.
3) Validierungsregeln und Plausibilitätschecks Einfache Regeln liefern überproportional viel Wirkung:
- Wertebereiche (z. B. Margen können nicht beliebig sein)
- Konsistenz über Zeit (Sprünge markieren)
- Cross-Checks (z. B. Summe der Segmente vs. Gesamtumsatz)
4) Stichproben-Audits mit „Source-to-Claim“-Prüfung Gerade für Entscheidungsvorlagen ist eine Prüfdisziplin entscheidend: Jede kritische Aussage muss auf eine Quelle zurückführbar sein.
Ein realistischer Qualitätsprozess für Teams unter Zeitdruck
Viele Teams scheitern, weil sie „Perfektion“ anstreben. Besser ist ein Stufenmodell:
- Pilot: Fokus auf Nutzen, aber mit klarer Kennzeichnung „nicht entscheidungsreif“.
- Limited Production: definierte Use Cases, definierte Quellen, verpflichtende Source-to-Claim Checks.
- Production: Qualitätsmetriken, regelmäßige Audits, Incident-Prozess.
So entsteht Qualität iterativ, ohne die Organisation zu blockieren.
3) Explainability: Erklärbarkeit ist kein Nice-to-have, sondern ein Kontrollinstrument
Explainability wird oft mit „Modell erklärt sich selbst“ verwechselt. Für Data Analysis in professionellen Kontexten bedeutet Explainability vor allem:
- Transparenz: Welche Daten und Schritte führten zum Ergebnis?
- Begründbarkeit: Warum ist diese Schlussfolgerung plausibel?
- Reproduzierbarkeit: Kann ein Dritter das Ergebnis nachvollziehen?
- Angreifbarkeit: Wo sind Unsicherheiten, Annahmen, Alternativen?
Unterschiedliche Explainability je nach Modelltyp
Nicht jede Methode passt zu jedem System:
- Tabellarische ML-Modelle (z. B. XGBoost): Feature-Attribution (z. B. SHAP) kann gut funktionieren.
- Deep Learning: oft schwieriger, hier helfen Surrogat-Modelle oder lokale Erklärungen.
- LLM-Systeme: „Warum“ ist häufig nicht zuverlässig aus dem Modell ableitbar. Daher zählt hier vor allem prozessuale Explainability: Quellen, Retrieval-Logik, Zitierpflicht, Abdeckung, Unsicherheitskennzeichnung.
Wichtig: Eine „Reasoning“-Erklärung eines LLMs ist nicht automatisch wahr. In vielen Fällen ist es besser, Explainability über Belege und nachvollziehbare Schritte zu lösen statt über eine introspektive Modellbegründung.
Explainability-Design für entscheidungsreife Outputs
Für PE/VC/Consulting sind diese Patterns besonders wirksam:
Claim, Evidence, Confidence Jede zentrale Aussage wird im Output so strukturiert:
- Claim (Aussage)
- Evidence (Quelle, Textstelle, Tabelle)
- Confidence (hoch/mittel/niedrig, plus warum)
Assumptions sichtbar machen Viele Analysen stehen und fallen mit Annahmen (TAM-Definition, Peer-Set, FX, Normalisierungen). Gute Explainability macht Annahmen explizit, statt sie im Fließtext zu verstecken.
„Was würde das Ergebnis ändern?“ Counterfactual-Fragen sind extrem hilfreich: Welche Variable oder Quelle würde die Schlussfolgerung kippen? Das ist praktisch Explainability als Sensitivitätslogik.
Explainability für Audit und Kundenarbeit
In Consulting und Corporate Strategy muss Explainability nicht nur intern überzeugen, sondern auch extern. Dafür braucht es:
- Exportierbare Belege (Quellenliste, Zitate, Tabellenherkunft)
- Versionierung (welcher Datenstand, welcher Run)
- Review-Workflow (wer hat freigegeben, welche Passagen wurden geändert)
4) So greifen Governance, Qualität und Explainability ineinander (und wo Teams scheitern)
Die drei Bereiche sind keine unabhängigen Checklisten. Typische Bruchstellen:
- Ohne Governance gibt es keine verbindlichen Qualitätsstandards, nur individuelle Sorgfalt.
- Ohne Datenqualität wird Explainability zur gut präsentierten Fehlannahme.
- Ohne Explainability kann Governance die Ergebnisse nicht auditieren, und Qualität kann nicht zielgerichtet verbessert werden.
Ein pragmatischer Leitgedanke lautet: „Erklärbarkeit ist die Oberfläche, Qualität ist das Fundament, Governance ist die Statik.“
5) Auswahlkriterien für eine AI-for-Data-Analysis-Plattform (Enterprise-Realität)
Wenn Sie Tools evaluieren, sind Demos oft auf Output-Qualität optimiert. Für den produktiven Einsatz sollten Sie zusätzlich systematisch prüfen:
Security und Datenkontrolle
Gerade in Deal-Kontexten sind Vertraulichkeit und Mandantenschutz zentral.
Achten Sie auf:
- Verschlüsselung (Transport und idealerweise Ende-zu-Ende)
- Datenminimierung und klare Aussagen zur Datenspeicherung
- Mandantenfähigkeit, Rollen- und Rechtekonzepte
- Audit Logs
Quellenintegration und Nachweisfähigkeit
Für Research und Due Diligence ist entscheidend, ob ein System Quellen sauber integriert und Ergebnisse belegbar macht.
Prüffragen:
- Können Sie eigene Quellen nahtlos integrieren (Datenräume, interne PDFs, Wissensbasen)?
- Gibt es eine konsistente Quellenlogik (Zitate, Fundstellen, Abdeckung)?
- Können Sie Q&A gezielt erweitern, ohne die Governance zu brechen?
Operative Steuerbarkeit (Change, Drift, Quality)
Ein produktives System braucht Mechanismen, um Qualität über Zeit zu halten:
- Versionierung von Prompts/Workflows
- Monitoring (Fehlerklassen, Retrieval-Qualität, Nutzerfeedback)
- Prozess für Incidents (z. B. falsche Zahl in IC-Unterlage)
6) Einordnung: Wie Researchly hier typischerweise eingesetzt wird
Researchly ist als KI-gestützte Research- und Due-Diligence-Plattform für PE, VC, Consulting und Corporates positioniert. Für die Themen dieses Artikels sind aus Ihrer Beschreibung vor allem drei Aspekte relevant:
- Glaubwürdige Einblicke und menschenähnliche Synthese: Das zielt direkt auf die Explainability-Erwartung in entscheidungsnahen Analysen, sofern Outputs sauber belegt und überprüfbar sind.
- Nahtlose Quellenintegration und individuelle Q&A-Erweiterungen: Das ist ein zentraler Hebel, um Datenqualität und Grounding zu verbessern, weil interne und externe Quellen gezielt steuerbar werden.
- Datensicherheit auf Unternehmensniveau mit End-to-End-Verschlüsselung und keiner internen Datenspeicherung (laut Ihren Angaben): Das adressiert Governance- und Security-Anforderungen, die in M&A- und Strategiekontexten häufig die Tool-Auswahl dominieren.
Wenn Sie Researchly oder vergleichbare Plattformen evaluieren, lassen Sie sich im Demo gezielt zeigen, wie Governance-Artefakte (Quellen, Versionierung, Nachvollziehbarkeit) im Alltag unterstützt werden. Genau dort entscheidet sich, ob AI for Data Analysis vom Pilot in die Organisation skaliert.

Belastbare KI-Analysen: Ein Stack statt drei getrennte Baustellen
Governance, Datenqualität und Explainability lassen sich nicht als Einmal-Checkliste abhaken – sie brauchen einen Workflow, in dem Quellen, Agenten-Outputs und Freigaben zusammenspielen. Wer hier integriert statt fragmentiert arbeitet, kommt schneller von Pilot zu entscheidungsreifen Analysen.
Die drei Outputs, die Sie erhalten:
- Research- und Due-Diligence-Ergebnisse mit durchgängiger Quellenführung – jede zentrale Aussage mit Source-to-Claim-Nachweis, geeignet für IC und Audit.
- Versionierte Agenten-Workflows und Konfigurationen – Reproduzierbarkeit, Change Log und klare Grenzen pro Use Case, ohne Governance-Overhead.
- Eigene Datenräume und Wissensbasen nahtlos eingebunden – Mandantenfähigkeit, Zugriffskontrolle und keine unnötige Datenspeicherung.
Researchly unterstützt PE, VC, Consulting und Corporates dabei, genau diesen Stack zu betreiben: AI-Agenten für Research und Due Diligence, konsistente Quellenlogik und Enterprise-Security in einer Plattform.