

TL/DR
Automatisiertes Internal Linking ist 2026 kein Feature, das du „einschaltest" – es ist ein Nebenprodukt eines richtig aufgesetzten Content-Systems. Wenn deine Architektur stimmt (Cluster, Wissensdatenbank, Refresh-Trigger), entstehen interne Links automatisch als logische Konsequenz. Der Fehler der meisten Teams: Sie behandeln Verlinkung als separaten Task statt als emergente Eigenschaft ihrer Content Operations.
Inhalt
- Reality Check 2026: Warum Internal Linking immer noch unterschätzt wird
- Die 4 Failure Modes manueller Teams
- Was die Automatisierungs-Experten empfehlen (Taktik-Übersicht)
- Das Closed-Loop-Modell: Internal Links als Nebenprodukt
- End-to-End Beispiel: Mein LLM-gestützter Workflow mit Open WebUI
- Build vs. Buy: Wann lohnt sich was?
- FAQ
1) Reality Check 2026: Warum Internal Linking immer noch unterschätzt wird
Google's John Mueller hat es mehrfach bestätigt: „Internal links help us a lot … probably one of the biggest things you can do on a website."
Trotzdem behandeln die meisten Teams interne Verlinkung wie eine Hausaufgabe: Am Ende des Artikels noch schnell 3 Links raussuchen, Copy-Paste, fertig.
Das Problem:
- Bei 10 Artikeln funktioniert das.
- Bei 100 Artikeln wird es mühsam.
- Bei 500 Artikeln ist es unmöglich – und die Architektur zerfällt.
Was interne Links für dein Ranking tun:
| Funktion | SEO-Effekt |
|---|---|
| Crawl-Steuerung | Google findet neue Seiten schneller |
| PageRank-Verteilung | Wichtige Seiten bekommen mehr „Link Juice" |
| Thematische Signale | Cluster-Zugehörigkeit wird klar |
| UX & Verweildauer | Leser navigieren tiefer, Bounce sinkt |
Der 2026-Twist: Mit GEO/AEO (Generative Engine Optimization) entscheiden interne Links auch darüber, welche Seiten KI-Systeme als zusammengehörig erkennen – und welche sie in Antworten zitieren.
2) Die 4 Failure Modes manueller Teams
Bevor du automatisierst, musst du verstehen, warum manuelle Prozesse scheitern. Es sind nicht die einzelnen Tasks – es ist das System.
Failure Mode 1: Orphan Pages durch Vergessen
Neue Artikel werden veröffentlicht, aber niemand verlinkt sie aus bestehenden Inhalten. Sie verhungern ohne PageRank. Das Team weiß oft nicht einmal, welche Seiten betroffen sind.
Failure Mode 2: Inkonsistente Anchor-Strategie
Mal „hier klicken", mal das exakte Keyword, mal gar kein Anchor. Ohne zentrale Bibliothek entstehen Muster, die weder für Nutzer noch für Google sinnvoll sind.
Failure Mode 3: Veraltete Referenzen
Alte Artikel verlinken nicht auf neue Inhalte. Je älter der Content, desto isolierter wird er – obwohl er oft die meiste Autorität hat.
Failure Mode 4: Zeitfresser „Link-Recherche"
Redakteure verbringen 15–30 Minuten pro Artikel damit, passende interne Links zu suchen. Bei 4 Artikeln pro Woche sind das 4–8 Stunden reine Suchzeit – ohne strategischen Wert.
Die Erkenntnis: Diese Probleme löst du nicht mit „mehr Disziplin". Du löst sie mit einem System, in dem Verlinkung keine separate Entscheidung mehr ist.
3) Was die Automatisierungs-Experten empfehlen (Taktik-Übersicht)
Bevor ich mein eigenes System vorstelle, ein Blick auf die etablierten Best Practices. Der umfassende Guide von BlogSEO fasst 10 bewährte Taktiken zusammen :
| Taktik | Kernidee |
|---|---|
| Hub-&-Spoke-Architektur | Pillar Pages + Cluster-Artikel systematisch verknüpfen |
| Keyword-Gruppen | Semantisch verwandte Phrasen-Bibliothek statt Einzel-Anchors |
| NLP-basierte Anchor-Rotation | Natürliche Formulierungen statt statischer Links |
| Orphan-Page-Audits | Monatlich verwaiste Seiten identifizieren und verlinken |
| Link-Tiefe kontrollieren | Wichtige Seiten max. 3 Klicks von der Startseite |
| Drip-Verlinkung | Links über mehrere Tage verteilen statt alle auf einmal |
| Dynamische Widgets | Trending/Popular-Seiten automatisch einblenden |
| Semantische Ähnlichkeit | Embeddings statt nur Keyword-Match für Link-Vorschläge |
| „Nächster Schritt"-Links | Klare Pathways am Artikelende |
| Performance-Tracking | Unterperformende Links automatisch ersetzen |
Meine Beobachtung: Diese Taktiken sind richtig – aber sie behandeln Symptome. Wer sie einzeln implementiert, baut 10 neue Prozesse. Das skaliert nicht.
Die bessere Frage: Wie baust du ein System, in dem diese Taktiken automatisch greifen, weil die Architektur stimmt?
4) Das Closed-Loop-Modell: Internal Links als Nebenprodukt
Statt Internal Linking als Task zu behandeln, baue ein System, in dem Links emergent entstehen. Ich nenne das den Content Knowledge Loop.
Das Modell: Content Knowledge Loop (5 Stufen)
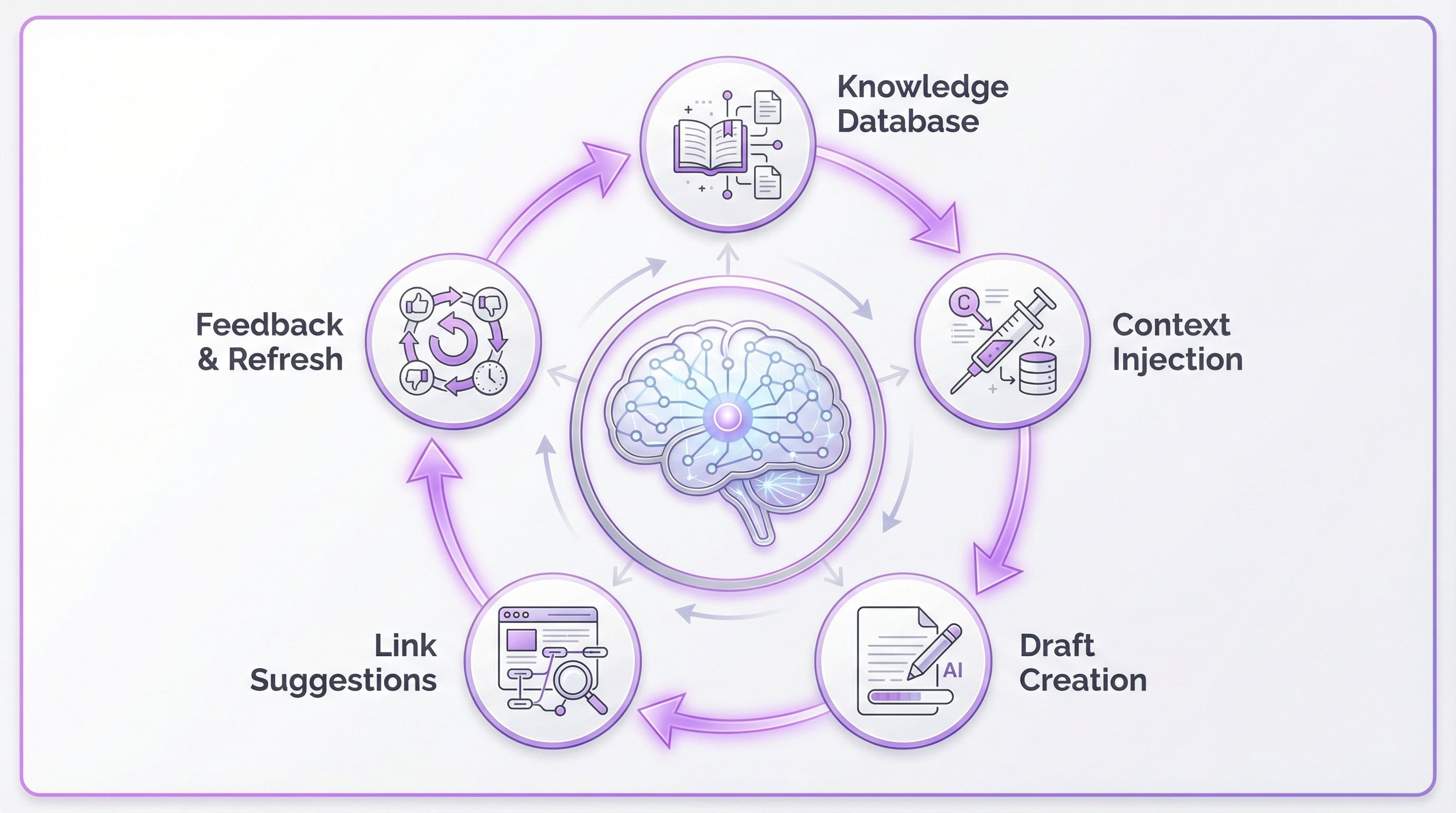
Hier die Copy&Paste-Variante:
┌─────────────────────────────────────────────────────┐
│ │
│ 1. WISSENSDATENBANK │
│ (Alle Artikel, URLs, Cluster, Entities) │
│ │
│ ↓ │
│ │
│ 2. DRAFT-ERSTELLUNG │
│ (Neuer Artikel wird geschrieben) │
│ │
│ ↓ │
│ │
│ 3. CONTEXT INJECTION │
│ (LLM kennt alle bestehenden Inhalte) │
│ │
│ ↓ │
│ │
│ 4. LINK-VORSCHLÄGE ALS OUTPUT │
│ (Nicht gesucht, sondern generiert) │
│ │
│ ↓ │
│ │
│ 5. FEEDBACK & REFRESH │
│ (Performance-Daten triggern Updates) │
│ │
└──────────────────────────────────────────────────────┘
↑ │
└────────────────────┘
Warum das funktioniert:
- Stufe 1 (Wissensdatenbank): Dein gesamter Blog existiert als durchsuchbare Struktur (URLs, Titel, Cluster, Kernthemen).
- Stufe 2 (Draft): Du schreibst den Artikel wie gewohnt.
- Stufe 3 (Context Injection): Ein LLM hat Zugriff auf die Wissensdatenbank und „weiß", welche Artikel existieren.
- Stufe 4 (Link-Output): Das LLM schlägt nicht nur Keywords vor – es gibt dir konkrete URLs, Anchors und Platzierungen zurück.
- Stufe 5 (Feedback): Wenn ein Artikel underperformt (z.B. -15% Impressions), wird er automatisch in die Refresh-Queue aufgenommen – inkl. neuer interner Links.
Der entscheidende Unterschied: Du suchst keine Links mehr. Du fragst ein System, das dein gesamtes Content-Universum kennt.
5) End-to-End Beispiel: Mein LLM-gestützter Workflow mit Open WebUI
Viele Teams versuchen, Internal Linking mit Spreadsheets und manueller Suche zu managen. Das skaliert nicht. Hier ist mein Setup – als konkretes Beispiel, das du adaptieren kannst.
Mein System: Open WebUI + LLM + strukturierte Blog-Liste
Ich speichere meine gesamte Blog-Liste (URLs, Titel, Cluster-Zuordnung, Kernentities) in Open WebUI als durchsuchbare Wissensdatenbank. Bei jedem neuen Artikel nutze ich ein LLM, um passende interne Links zu identifizieren.
Der Workflow (Schritt für Schritt)
| Schritt | Aktion | Tool/Komponente |
|---|---|---|
| 1 | Neuen Artikel-Draft schreiben | Beliebiger Editor |
| 2 | Draft in Open WebUI einfügen | Open WebUI Chat |
| 3 | Prompt: „Finde 5 passende interne Links aus meiner Blog-Liste für diesen Artikel. Berücksichtige semantische Nähe und Cluster-Zugehörigkeit." | LLM (Claude, GPT-4) |
| 4 | LLM gibt Vorschläge zurück: URL + empfohlener Anchor + Absatz zur Platzierung | — |
| 5 | Vorschläge reviewen und einfügen | Manuell (2–3 Min.) |
| 6 | Artikel veröffentlichen | CMS |
| 7 | Nach 30 Tagen: Performance prüfen, ggf. Refresh triggern | Analytics + Loop |
Mein Standard-Prompt (zum Kopieren)
Hier ist mein neuer Artikel über [THEMA].
Finde aus meiner Blog-Datenbank die 5 relevantesten Artikel für interne Verlinkung.
Gib für jeden zurück:
1. URL
2. Empfohlener Anchor-Text (3–6 Wörter, natürlich klingend)
3. Welcher Absatz im neuen Artikel passt am besten
Priorisiere:
- Hub-Artikel (Pillar Pages)
- Thematisch verwandte Spokes
- Seiten mit hoher strategischer Bedeutung (Conversion-Seiten)
Vermeide:
- Mehr als einen Link pro 250 Wörter
- Doppelte Anchors auf verschiedene URLs
Beispiel-Output (für diesen Artikel)
| Empfohlene URL | Anchor-Text | Platzierung |
|---|---|---|
| AI-SEO & GEO Content 2026 Guide | KI-gestützte Content-Strategien | Abschnitt über GEO/AEO |
| Auto-Publishing mit KI-SEO | automatisierte Veröffentlichung | Abschnitt über den Loop |
| Content-Automatisierung mit KI-Agenten | KI-Agenten für Content-Workflows | Nach dem Workflow-Abschnitt |
| n8n ETL-Pipeline für Blog-Optimierung | automatisierte Refresh-Pipelines | Abschnitt über Feedback-Loop |
Warum das funktioniert
- Das LLM „kennt" alle meine Artikel durch die Wissensdatenbank – ich muss nicht suchen.
- Semantische Zusammenhänge werden erkannt, nicht nur Keyword-Matches.
- Zeitersparnis: 20–30 Minuten pro Artikel → 2–3 Minuten.
- Konsistenz: Anchor-Strategie bleibt einheitlich, weil der Prompt sie definiert.
6) Build vs. Buy: Wann lohnt sich was?
Die Frage ist nicht „Automatisierung ja oder nein", sondern: Wo investierst du deine Ressourcen?
Option A: Eigenes System bauen (Build)
Geeignet für:
- Teams mit technischem Know-how (n8n, APIs, LLM-Integration)
- Spezifische Anforderungen, die kein Tool abdeckt
- Volle Kontrolle über Daten und Prozesse
Setup-Komponenten:
- Wissensdatenbank (Notion, Airtable, oder Vektor-DB)
- LLM-Zugang (OpenAI API, Claude, lokale Modelle)
- Interface (Open WebUI, Custom Chat, oder n8n Workflow)
- Monitoring (Search Console API, eigene Dashboards)
Aufwand: 2–4 Wochen Setup, dann laufende Wartung
Option B: Spezialisierte Plattform nutzen (Buy)
Geeignet für:
- Teams ohne technische Ressourcen
- Schneller Start ohne Setup-Overhead
- Integrierte Workflows (Monitoring + Content + Publishing)
Was Plattformen typischerweise bieten:
- Automatische Cluster-Erkennung
- Link-Vorschläge beim Schreiben
- Orphan-Page-Audits
- Performance-Tracking
Researchlys GEO-Content-System überwacht nicht nur Rankings, sondern auch KI-Sichtbarkeit (ChatGPT, Perplexity, Claude), erkennt Content-Chancen und füllt den Content-Kalender automatisch – inkl. interner Verlinkung als Teil des Workflows.
Entscheidungsmatrix
| Kriterium | Build | Buy |
|---|---|---|
| Time-to-Value | 2–4 Wochen | Sofort |
| Flexibilität | Hoch | Mittel |
| Wartungsaufwand | Hoch | Niedrig |
| Kosten (initial) | Zeit + Entwicklung | Subscription |
| Kosten (laufend) | API-Kosten + Wartung | Subscription |
| Beste Wahl für | Tech-affine Teams, spezielle Anforderungen | Marketing-Teams, schneller ROI |
Meine Empfehlung: Starte mit einem einfachen Build (Open WebUI + Blog-Liste), um das Prinzip zu verstehen. Wenn der Prozess validiert ist und du skalieren willst, evaluiere spezialisierte Tools, wie bspw. unser KI-Tool, mit dem organischen Traffic zu 100 % automatisch mit KI-gesteuerten, automatisch veröffentlichten SEO-Blogartikeln skalierst.
Wie starte ich am schnellsten?
- Exportiere deine Blog-URLs in eine strukturierte Liste (Titel, URL, Cluster)
- Lade sie in Open WebUI oder ein ähnliches Tool
- Nutze den Prompt aus Abschnitt 5 für deinen nächsten Artikel
- Iteriere basierend auf den Ergebnissen
Zusammenfassung: Die 3 Kernprinzipien
-
Internal Linking ist kein Task – es ist ein Systemergebnis. Wenn deine Content-Architektur (Cluster, Wissensdatenbank, Refresh-Trigger) stimmt, entstehen Links als Nebenprodukt.
-
Context beats Keywords. Ein LLM, das dein gesamtes Content-Universum kennt, findet bessere Verbindungen als jede Keyword-Suche.
-
Der Loop macht den Unterschied. Einmalige Verlinkung ist 2024. Der Feedback-Loop (Performance → Refresh → neue Links) ist 2026.
Nächster Schritt: AI-SEO & GEO Content 2026: Der CMO-Guide – verstehe das größere System, in dem Internal Linking nur ein Baustein ist.