Layer 1: Quellenkontrolle, bevor das Modell überhaupt etwas sieht
Die erste Schicht entscheidet, aus welchem Datenuniversum das Modell schöpfen darf. Klingt trivial, ist es nicht. In der Praxis ziehen viele Workflows von "irgendwo im Web", weil der Suchschritt dem Modell überlassen wurde.
Drei Bausteine machen den Unterschied:
Allow-List authoritativer Quellen. Für eine Tech-Due-Diligence sind das Handelsregister-Daten, Patentdatenbanken wie Espacenet oder DPMA, geprüfte Finanzberichte, Konferenzpapers, regulatorische Filings. Für eine Marktrecherche dazu Crunchbase, PitchBook, akademische Publikationen. Welche Datenbanken im Detail relevant sind, hängt vom Use Case ab. Die Whitelist wird einmal kuratiert und dann konsequent erzwungen.
Forbidden-List klassischer Halluzinations-Trigger. Content-Farmen, KI-generierte Aggregator-Seiten, SEO-Spam, Foren ohne Verifikation. Wer dem Modell Zugriff auf "alles, was Google rankt", gibt, importiert die Bias dieser Sammlung. In der Recherche zählt das Gegenteil: ein engeres, aber sauber kuratiertes Quellenuniversum.
Domain-Reputation als Score. Wenn das System Quellen nutzt, die nicht auf der Whitelist stehen (was vorkommt, wenn der Suchschritt offen bleibt), bekommt jede Domain einen Reputations-Score. Behördliche Quellen oben, Fachmedien in der Mitte, KI-generierte Blogs unten. Der Score fließt später ins Konfidenz-Scoring ein.
Wer Layer 1 ignoriert, wird auf Layer 4 nie wirklich konfident sein. Die Qualität der Antwort ist gedeckelt durch die Qualität der Quellenbasis. Ein RAG-System, das aus erstklassigen Primärquellen zieht, halluziniert messbar seltener, was die IOSCO in ihrem Bericht zu KI in Kapitalmärkten so dokumentiert hat.
Layer 2: Citation Enforcement, also keine Aussage ohne Beleg
Die zweite Schicht ist eine Regel, kein Tool. Jede Aussage im Output muss an einen Beleg gebunden sein. Keine Ausnahmen.
In der Praxis sieht das so aus: Der Agent generiert seine Antwort mit Inline-Footnotes oder bracket citations. Vor der Auslieferung prüft ein Validator, ob jeder Satz, der eine faktische Aussage trifft, mindestens eine Quellreferenz trägt. Sätze ohne Quelle werden entweder zurückgehalten oder als unbelegt markiert.
Drei Härtungsstufen lassen sich dabei staffeln. Auf Stufe eins reicht eine Quelle pro Aussage. Auf Stufe zwei muss die Quelle im erlaubten Quellenuniversum aus Layer 1 liegen. Auf Stufe drei wird zusätzlich geprüft, ob der zitierte Inhalt tatsächlich im Zieldokument vorkommt, also ein literaler Quellabgleich passiert. Diese Prüfung verhindert eine besonders heimtückische Halluzinationsform: die fabrizierte Quelle. Ein Modell, das sich eine Zahl ausdenkt, denkt sich oft gleich eine plausibel aussehende Studie dazu aus. URL und Autor*In stimmen auf den ersten Blick, der zitierte Inhalt steht aber nirgends in der Quelle.
Die Stufe drei ist die wichtigste und wird am häufigsten weggelassen, weil sie teurer ist. Wer sie nicht implementiert, sollte sie wenigstens stichprobenartig manuell ziehen, mit drei zufälligen Aussagen pro Bericht, davon mindestens eine quantitative.
Layer 3: Triangulation, und Unabhängigkeit ist die ganze Disziplin
Die dritte Schicht trennt belegte Aussagen von belastbaren Aussagen. Eine Quelle ist ein Hinweis. Zwei sind ein Indiz. Drei unabhängige sind ein Befund.
Das Wort "unabhängig" trägt hier das ganze Gewicht. Drei Online-Artikel, die dieselbe Pressemitteilung zitieren, sind keine drei Quellen. Das ist eine Quelle in dreifacher Verkleidung. Eine ernsthafte Triangulation prüft strukturelle Unabhängigkeit:
- Stammen die Quellen aus verschiedenen Quelltypen (Primärquelle vs. Sekundärquelle vs. Tertiärquelle)?
- Sind die Erhebungszeitpunkte unterschiedlich, oder reden alle über denselben Stichtag?
- Steht hinter den Quellen dieselbe wirtschaftliche Interessenlage (z.B. dasselbe Beratungshaus, dasselbe PR-Team)?
Eine pragmatische 2-aus-N-Regel reicht für die meisten Fälle. Jede wesentliche Aussage muss durch mindestens zwei strukturell unabhängige Quellen gestützt sein. Für rechtlich oder strategisch hochriskante Aussagen (Patentposition, Umsatzbehauptungen, Marktanteilszahlen) gilt 3-aus-N. Wenn keine zweite unabhängige Quelle gefunden wird, gehört die Aussage explizit als unverifiziert markiert, nicht weggelassen. Das macht den Unterschied zwischen einer ehrlichen und einer geschönten Analyse.
In der Praxis bauen wir das in Researchly-Agenten als separaten Verifikations-Schritt ein. Der Agent, der die Analyse schreibt, ist nicht derselbe, der die Triangulation prüft. Diese Aufgabentrennung verhindert, dass das Modell seine eigene Halluzination bestätigt.
Layer 4: Konfidenz-Scoring und Halluzinations-Detektion
Die vierte Schicht beantwortet die Frage: Wie sicher ist das System bei diesem konkreten Befund? Konfidenz ist hier keine Selbsteinschätzung des Modells, sondern eine zusammengesetzte Größe aus Quellenqualität, Anzahl unabhängiger Belege, Aktualität und Self-Critique-Ergebnis.
Drei Mechanismen liefern brauchbare Signale.
Self-Critique durch einen zweiten Agenten. Der Analysetext wird an einen separaten Modellaufruf übergeben, dessen einzige Aufgabe es ist, Schwachstellen zu finden: fehlende Belege, widersprüchliche Aussagen, Sprünge in der Argumentation, Aussagen ohne Quelle. Die Authority Partners haben das als "Chain-of-Verification" beschrieben, das Muster ist im Kern simpel: trenne Erzeugung und Kritik, lasse beide gegeneinander arbeiten.
Spot-Checks für Zahlen, Daten und Zitate. Quantitative Aussagen sind die fehleranfälligsten Bestandteile von KI-generierten Berichten. Ein automatisierter Spot-Check zieht zufällig drei bis fünf Zahlen pro Bericht und vergleicht sie mit der Primärquelle. Bei mehr als einer Abweichung wird der Bericht zurückgewiesen und neu erzeugt. Datumsfelder funktionieren analog. Wenn das Patent von 2019 ist, das Modell aber "vor zwei Jahren angemeldet" schreibt, fällt das auf.
Konfidenz-Score pro Aussage. Jeder Befund bekommt einen Wert zwischen niedrig, mittel und hoch. Hohe Konfidenz bedeutet: Whitelist-Quelle, mehrere unabhängige Belege, zeitlich aktuell, vom Self-Critique nicht beanstandet. Niedrige Konfidenz heißt: einzelne nicht-authoritative Quelle, kein Cross-Check, alt. Der Score steuert dann die Sprache im Bericht und triggert auf Layer 5 die Pflicht-Reviews.
Die NIST AI Risk Management Framework GAI-Profile (NIST AI 600-1, DOI: 10.6028/NIST.AI.600-1) nennen Konfabulation explizit als eigenständiges Risiko und fordern messbare Kontrollen entlang Govern, Map, Measure und Manage. Wer Konfidenz-Scoring sauber implementiert, hat die Measure-Funktion abgedeckt. Wer es weglässt, hat keine Antwort, wenn ein Auditor fragt: Wie messt ihr das Risiko?
Layer 5: Review-Gates, also wo Menschen unterschreiben müssen
Die fünfte Schicht wird regelmäßig als unwichtig abgetan, weil sie nicht "AI" ist. Sie ist trotzdem die kritischste. Vollautomatisierte Recherche, die in Investment-Entscheidungen einfließt, ist regulatorisch nicht haltbar. FINRA, die EU AI Act-Klassifikation für High-Risk-Anwendungen und die IOSCO-Empfehlungen für Kapitalmärkte bestehen alle auf Mensch-KI-Zusammenarbeit, und zwar operativ, nicht symbolisch.
Drei Fragen entscheiden über die Qualität eines Review-Gates:
Wer reviewt was und wann? Pflicht-Review für alles, was hohe Konfidenz nicht erreicht. Pflicht-Review für quantitative Aussagen über einer definierten Materialitätsschwelle. Pflicht-Review für jede Aussage, die in einer rechtsverbindlichen Form weiterverwendet wird. Optional-Review für den Rest, mit Stichproben.
Was passiert mit der Entscheidung? Jede Entscheidung im Review-Gate wird mit Zeitstempel, Reviewer*In und Begründung dokumentiert. Wenn ein Befund mit niedriger Konfidenz trotzdem freigegeben wird, muss das begründet sein. Diese Dokumentation ist der Audit-Trail, der nach dem Closing zählt. Bloomberg Law hat mehrere Fälle beschrieben, in denen Käuferseiten in der Post-Closing-Litigation belegen mussten, auf welcher Quellengrundlage eine Investment-Entscheidung gefällt wurde. Wer den Trail hat, beantwortet das in zwei Minuten, alle anderen rekonstruieren wochenlang einen Pfad, den es nie gab.
Wie wird Reviewer-Fatigue verhindert? Wenn jeder Befund einen Flag bekommt, wird am Ende kein Flag mehr ernst genommen. Der Konfidenz-Score aus Layer 4 sollte so kalibriert sein, dass nur ein Bruchteil aller Aussagen in den Pflicht-Review wandert, nämlich diejenigen, bei denen das System ehrlich sagt, dass es selbst unsicher ist. Das ist die einzige Art, wie Review-Gates langfristig funktionieren.
Eine kleine Scorecard: Wie reif ist dein Research-Guardrail-Stack?
Vor einer ernsthaften Investition in den Stack lohnt sich eine Bestandsaufnahme. Drei Reifegrade pro Layer.
| Layer |
Reifegrad 1 (Anfänger) |
Reifegrad 2 (Operativ) |
Reifegrad 3 (Auditfähig) |
| Quellenkontrolle |
Offene Web-Suche, keine Whitelist |
Whitelist für Pflicht-Themen |
Whitelist + Blacklist + Domain-Reputation-Score |
| Citation Enforcement |
Quellen optional, manchmal angefordert |
Inline-Zitate verpflichtend |
Literaler Quellabgleich + Reject ohne Quelle |
| Triangulation |
Einzelquelle reicht |
2-aus-N für wesentliche Aussagen |
2-aus-N + dokumentierte Unabhängigkeit |
| Konfidenz & Detektion |
Kein Score, keine Self-Critique |
Self-Critique durch zweiten Agenten |
Konfidenz pro Aussage + Spot-Checks für Zahlen |
| Review-Gates |
Sporadisches Drüberlesen |
Pflicht-Review für High-Risk |
Dokumentierter Audit-Trail mit Sign-off |
Reifegrad 1 entspricht dem typischen Stand vieler Pilotprojekte. Auditfähig ist man auf Reifegrad 3. Wer in einem regulierten Umfeld arbeitet (VC mit institutionellen LPs, PE mit Bankenfinanzierung, M&A in EU-AI-Act-relevanten Sektoren), sollte Reifegrad 3 als Zielbild setzen und Layer für Layer hochziehen, statt alles gleichzeitig anzugehen.
Die typische Sequenz: Layer 2 zuerst (kostet wenig, bringt am meisten Disziplin), dann Layer 1 (Quellenuniversum festziehen), dann Layer 5 (Review-Verfahren formalisieren), dann Layer 3 und 4 (technisch anspruchsvoller, brauchen Tooling).
Anti-Patterns, die regelmäßig schiefgehen
Vier Muster tauchen in fast jedem Projekt auf, in dem AI Guardrails für Research nicht funktionieren.
"Trust the model, prompt it better." Bessere Prompts senken die Halluzinationsrate, sie eliminieren sie nicht. Ein Prompt ist kein Kontrollmechanismus, sondern eine Optimierung. Wer Verifikation durch Prompting ersetzt, verschiebt das Problem in den Output, statt es im Prozess zu fangen.
Single-Source-Verifikation. Drei Artikel, die dieselbe Pressemitteilung zitieren, sind keine Triangulation. Das ist Pseudo-Verifikation, die Sicherheit suggeriert, wo keine ist. Ohne Unabhängigkeits-Check ist Triangulation eine Übung in Selbsttäuschung.
Reviewer-Fatigue. Wenn die Konfidenz-Schwelle zu konservativ kalibriert ist, landet alles im Pflicht-Review. Die Reviewer*Innen lernen, schnell durchzunicken, und nach drei Wochen ist die Schicht operativ wertlos. Konfidenz-Scoring muss diskriminieren: wenig flaggen, aber das Geflaggte ernst meinen.
Fehlender Audit-Trail. Der Bericht ist freigegeben, das Memo ist raus, die Investition läuft. Sechs Monate später muss jemand erklären, woher die Marktgrößen-Annahme stammte. Ohne dokumentierten Pfad von Aussage zu Quelle zu Reviewer-Entscheidung wird das eine schwierige Konversation. Mit Audit-Trail dauert sie zwei Minuten.
Diese vier Anti-Patterns sind nicht hypothetisch. Sie treten in Kombination auf, und sie sind die häufigsten Gründe, warum AI in der Recherche entweder wieder zurückgefahren oder zu einem materiellen Risiko wird.
Was Regulator*Innen erwarten, und wo das in 2026 strenger wird
Die regulatorische Landschaft für AI in Finance und Investment hat sich 2025 und 2026 deutlich verdichtet. Drei Entwicklungen sind für Research-Workflows direkt relevant.
FINRA hat in ihrem 2026er Regulatory Oversight Report erstmals einen eigenen Abschnitt zu Generative AI veröffentlicht. Broker-Dealer werden explizit aufgefordert, Verfahren zu entwickeln, die Halluzinationen adressieren, und KI-Agenten zu prüfen, die "über ihre Anweisungen hinaus handeln" könnten.
Der EU AI Act stuft Credit Scoring als High-Risk-Anwendung ein. Daraus folgen Dokumentations-, Transparenz-, Oversight- und Continuous-Monitoring-Pflichten, die zwischen 2026 und 2027 in Stufen verbindlich werden. Firmen, die in Europa operieren, bauen jetzt schon interne Model-Inventories und Audit-Trails auf.
NIST AI RMF und das Generative AI Profile gelten in den USA und faktisch auch in Europa als Audit-Referenz. Wer den eigenen Stack daran ausrichtet, hat ein Vokabular und einen Kontrollrahmen, der in praktisch jedem ernsthaften AI-Governance-Setup anschlussfähig ist.
Was 2024 in diesen Themen noch Best Practice war, wird 2026 zur Pflicht. Wer den Research-Guardrail-Stack erst aufbaut, wenn der erste Auditor an die Tür klopft, ist zu spät.
Wenn das Audit kommt, willst du die Schicht schon haben
Der Trend ist eindeutig. Halluzinationen werden in den nächsten 18 Monaten nicht verschwinden, und Reviewer-Anforderungen werden weiter steigen. LPs, Klient*Innen und Aufsicht werden nicht mehr fragen, ob ihr KI einsetzt, sondern wie ihr sie kontrolliert. Wer dann zeigen kann, dass jede Aussage zur Quelle, jede Quelle zur Triangulation und jede Triangulation zum Reviewer zurückführbar ist, gewinnt einen materiellen Vorteil gegenüber Teams, die noch erklären müssen, warum genau diese Empfehlung in genau diesem Memo stand.
Researchly baut diesen Stack als Standard in Research-, Due-Diligence- und Market-Intelligence-Workflows ein.
Die drei Outputs, die du erhältst:
- Vollständig zitierte Research-Berichte mit Konfidenz-Score pro Aussage, statt formal sauberer Texte ohne Belege
- Triangulierte Befunde aus Whitelist-Quellen (Handelsregister, Patentdatenbanken, geprüfte Filings, Fachmedien) statt undokumentierter Web-Suche
- Audit-Trail vom Memo bis zur Primärquelle, sodass nach dem Closing in zwei Minuten klar ist, woher welche Aussage kam
Statt 34 fragmentierter Tools eine zentrale Plattform, die Quellenkontrolle, Citation Enforcement, Triangulation, Konfidenz-Scoring und Review-Gates in einen Workflow integriert.
Demo vereinbaren und 14 Tage kostenlos testen →


 Beide Stacks gehören in eine ernsthafte KI-Architektur. Aber wer eine Investment Due Diligence absichert und dabei nur den ersten Stack einkauft, schützt das falsche Ende des Risikos.
Beide Stacks gehören in eine ernsthafte KI-Architektur. Aber wer eine Investment Due Diligence absichert und dabei nur den ersten Stack einkauft, schützt das falsche Ende des Risikos.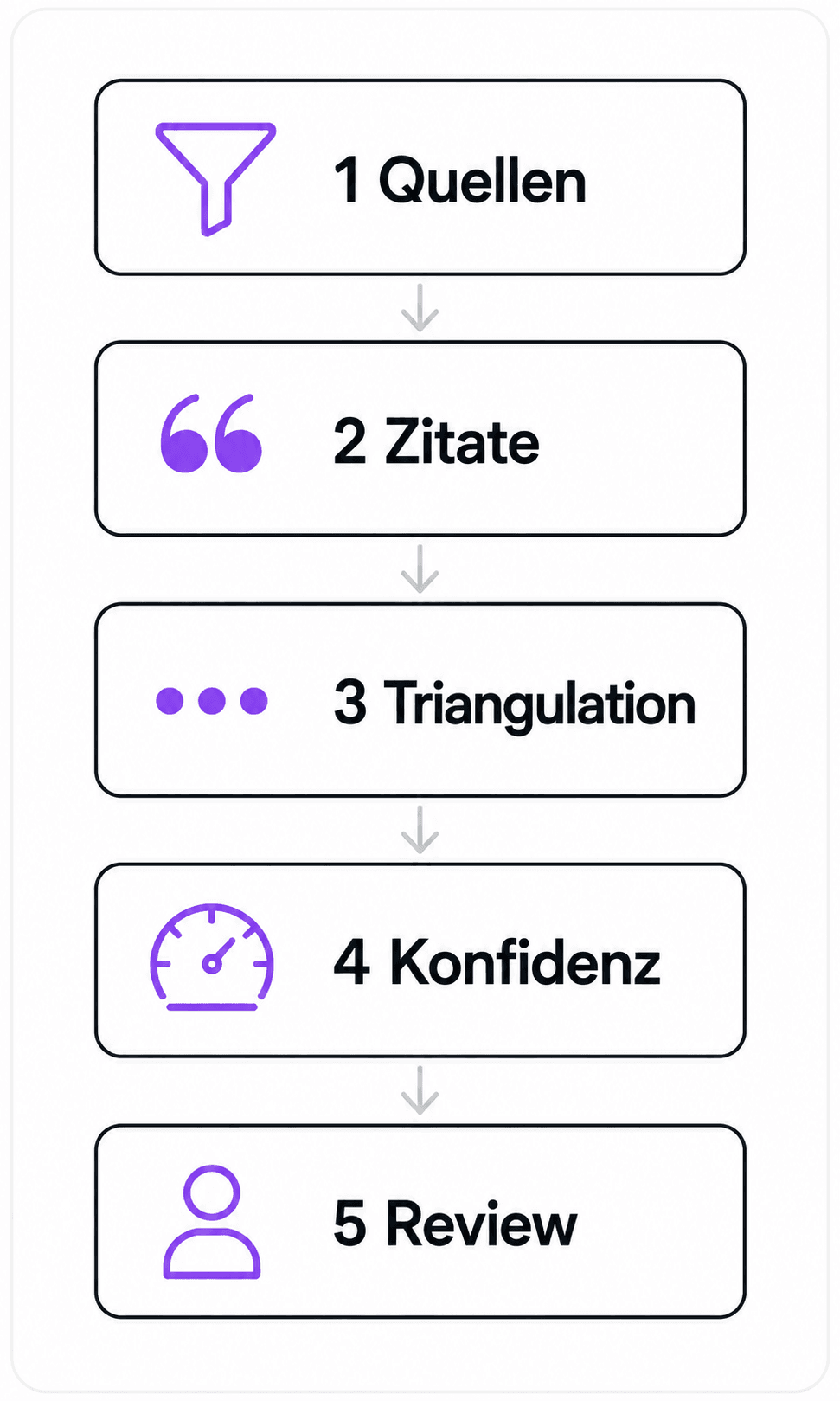 Die Logik dahinter ist nicht originell. Sie spiegelt das, was strukturierte Analysetechniken aus dem Nachrichtendienst seit Jahrzehnten machen, also Bias sichtbar machen, Quellen gewichten, Annahmen prüfen, Reasoning dokumentieren. Was neu ist: Mit KI im Workflow lässt sich jeder dieser Schritte teilweise automatisieren, statt ihn aus Zeitmangel zu überspringen.
Die Logik dahinter ist nicht originell. Sie spiegelt das, was strukturierte Analysetechniken aus dem Nachrichtendienst seit Jahrzehnten machen, also Bias sichtbar machen, Quellen gewichten, Annahmen prüfen, Reasoning dokumentieren. Was neu ist: Mit KI im Workflow lässt sich jeder dieser Schritte teilweise automatisieren, statt ihn aus Zeitmangel zu überspringen.